

AI compilers struggle with a fundamental tradeoff: they aim to abstract low-level details for usability and scalability, yet modern GenAI workloads demand programmability and hardware control to deliver top performance. CUDA C++ provides this level of control, but it’s notoriously unwieldy and painful to use. Meanwhile, AI development happens in Python—so naturally, the industry has tried to bridge the gap by bringing GPU programming and Python together.
But there’s a catch: Python can’t run on a GPU. To bridge this gap, researchers build Embedded Domain-Specific Languages (eDSLs)—Python-based abstractions that look like Python but compile to efficient GPU code under the hood. The idea is simple: give engineers the power of CUDA without the pain of C++. But does it actually work?
In this post, we’ll break down how Python eDSLs work, their strengths and weaknesses, and take a close look at Triton—one of the most popular approaches in this space—and a few others. Can Python eDSLs deliver both performance and usability, or are they just another detour on the road to democratized AI compute?
Let’s dive in. 🚀
What’s an Embedded Domain Specific Language (eDSL)?
Domain Specific Languages are used when a specific domain has a unique way to express things that makes developers more productive—perhaps the most well known are HTML, SQL, and regular expressions. An “eDSL” is a DSL that re-uses an existing language's syntax—but changes how the code works with compiler techniques. eDSLs power many systems, from distributed computing (PySpark) to deep learning frameworks (TensorFlow, PyTorch) to GPU programming (Triton).
For example, PySpark lets users express data transformations in Python, but constructs an optimized execution plan that runs efficiently across a cluster. Similarly, TensorFlow's tf.function and PyTorch's torch.fx convert Python-like code into optimized computation graphs. These eDSLs abstract away low-level details, making it easier to write efficient code without expertise in distributed systems, GPU programming, or compiler design.
How does an eDSL work?
eDSLs work their magic by capturing Python code before it runs and transforming it into a form they can process. They typically leverage decorators, a Python feature that intercepts functions before they run. When you apply @triton.jit, Python hands the function to Triton rather than executing it directly.
Here's a simple Triton example:
When Triton receives this code, it parses the function into an Abstract Syntax Tree (AST) that represents the function's structure, including operations and data dependencies. This representation allows Triton to analyze patterns, apply optimizations, and generate efficient GPU code that performs the same operations.
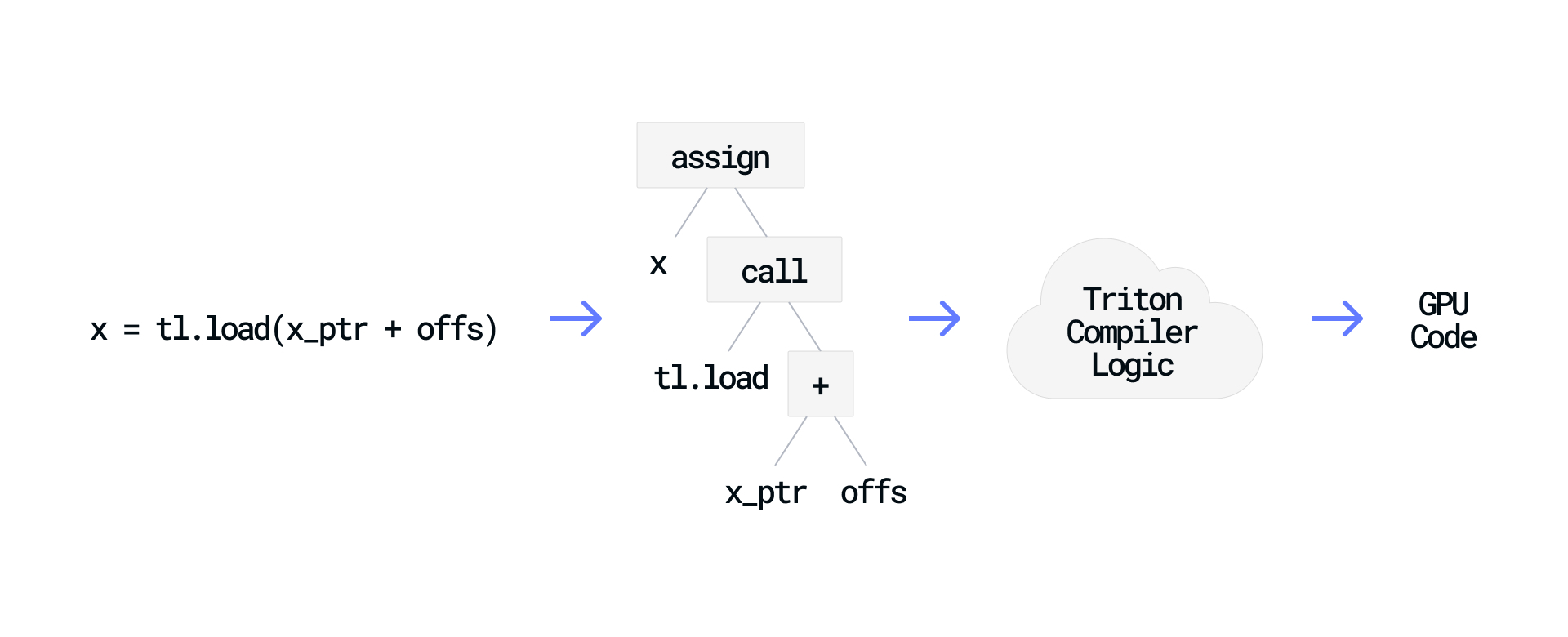
By leveraging Python's existing syntax and tooling, eDSL creators can focus on building compiler logic rather than designing an entirely new language with its own parser, syntax, and toolchain.
The advantage of eDSLs
eDSLs provide huge advantages for those building a domain-specific compiler: by embedding the language inside Python, developers can focus on compiler logic instead of reinventing an entire programming language. Designing new syntax, writing parsers, and building IDE tooling is a massive effort—by leveraging Python's existing syntax and AST tools, eDSL creators skip all of that and get straight to solving the problem at hand.
Users of the eDSL benefit too: Python eDSLs let developers stay in familiar territory. They get to use the same Python IDEs, autocompletion, debugging tools, package managers (e.g. pip and conda), and ecosystem of libraries. Instead of learning a completely new language like CUDA C++, they write code in Python—and the eDSL guides execution under the hood.
However, this convenience comes with significant tradeoffs that can frustrate developers who expect eDSLs to behave like regular Python code.
The challenges with eDSLs
Of course, there’s no free lunch. eDSLs come with trade-offs, and some can be deeply frustrating.
It looks like Python, but it isn't Python
This is the most confusing part of eDSLs. While the code looks like regular Python, it doesn’t behave like Python in crucial ways:
Why? Because an eDSL isn’t executing Python—it’s capturing and transforming the function into something else. It decides what constructs to support, and many everyday Python features (like dynamic lists, exception handling, or recursion) may simply not work. This can lead to silent failures or cryptic errors when something you’d expect to work in Python suddenly doesn’t.
Errors and Tooling Limitations
Debugging eDSL code can be a nightmare. When your code fails, you often don’t get the friendly Python error messages you’re used to. Instead, you’re staring at an opaque stack trace from deep inside of some compiler internals, with little clue what went wrong. Worse, standard tools like Python debuggers often don’t work at all, forcing you to rely on whatever debugging facilities the eDSL provides (if any). Further, while eDSLs exist within Python, they cannot use Python libraries directly.
Limited Expressiveness
eDSLs work by piggybacking on Python’s syntax, which means they can’t introduce new syntax that might be useful for their domain. A language like CUDA C++ can add custom keywords, new constructs, or domain-specific optimizations, while an eDSL is locked into a sublanguage of Python, which limits what it can express cleanly.
Ultimately, the quality of a specific eDSL determines how painful these trade-offs feel. A well-implemented eDSL can provide a smooth experience, while a poorly designed one can be a frustrating minefield of broken expectations. So does an eDSL like Triton get it right? And how does it compare to CUDA?
Triton: OpenAI's Python eDSL for GPU Programming
Triton began as a research project from Philippe Tillet at Harvard University, first published in 2019 after years working on OpenCL (see my earlier post on OpenCL). The project gained significant momentum when Tillet joined OpenAI, and when PyTorch 2 decided to embrace it.
Unlike general-purpose AI compilers, Triton focuses on accessibility for Python developers while still allowing for deep optimization. It strikes a balance between high-level simplicity and low-level control—giving developers just enough flexibility to fine-tune performance without drowning in CUDA’s complexity.
Let’s explore what makes Triton so useful.
Block-centric programming model
Traditional GPU programming forces developers to think in terms of individual threads, managing synchronization and complex indexing by hand. Triton simplifies this by operating at the block level—where GPUs naturally perform their work—eliminating unnecessary low-level coordination:
This model abstracts away thread management and simplifies basic indexing, but it also makes it much easier to leverage TensorCores—the specialized hardware responsible for most of a GPU’s FLOPS:
What would require dozens of lines of complex CUDA code becomes a single function call, while still achieving high performance. Triton handles the data layout transformations and hardware-specific optimizations automatically.
Simplified optimizations
One of CUDA's most frustrating aspects is managing complex index calculations for multi-dimensional data. Triton dramatically simplifies this:
These array manipulations feel similar to NumPy but compile to efficient GPU code with no runtime overhead.
Triton also includes compiler-driven optimizations—like vectorization—and enables simplified double buffering and software pipelining, which overlap memory transfers with computation. In CUDA, these techniques require deep GPU expertise; in Triton, they’re exposed in a way that non-experts can actually use. For a deeper dive, OpenAI provides detailed tutorials.
Triton makes GPU programming far more accessible, but that accessibility comes with tradeoffs. Let’s take a look at some of the key challenges.
Where Triton Falls Short
Triton is widely used and very successful for some cases (e.g. researchers working on training frontier models and specialty use cases). However, it isn’t widely adopted for all applications: in particular, it’s not useful for AI inference use-cases, which require maximum efficiency. Furthermore, despite predictions years ago by industry leaders, Triton has not united the ecosystem or challenged CUDA's dominance. Let’s dig in to understand the additional challenges Triton faces on top of the general limitations of all eDSLs (described earlier).
Significant GPU Performance/TCO Loss (compared to CUDA C++)
Triton trades performance for productivity (as explained by its creator). While this makes it easier to write GPU code, it also prevents Triton from achieving peak efficiency. The amount varies, but it is common to lose 20% on NVIDIA’s H100—which dominates AI compute today.
The problem? Compilers can’t optimize as well as a skilled CUDA developer, particularly for today’s advanced GPUs. In my decades of building compilers, I’ve never seen the myth of a “sufficiently smart compiler” actually work out! This is why leading AI labs, including DeepSeek, still rely on CUDA instead of Triton for demanding workloads: a 20% difference is untenable in GenAI: at scale it is the difference between a $1B cloud bill and an $800M one!
Governance: OpenAI’s Control and Focus
Triton is open source, but OpenAI owns its roadmap. That’s problematic because OpenAI competes directly with other frontier model labs, raising the question: will it prioritize the needs of the broader AI community, or just its own?
Many engineers have shared frustration about how difficult it is to contribute enhancements to Triton, particularly when changes don’t align with OpenAI’s internal priorities. One recurring complaint is that support for alternative hardware lags far behind—because OpenAI has little incentive to optimize for accelerators it doesn’t use. Triton’s leadership admits that “support for new users is virtually nonexistent”, and they don’t have bandwidth to keep up with community needs.
Poor Tooling and Debugger Support
CUDA's complexity is offset by a mature ecosystem of tools—Nsight Compute, profiler APIs, and memory debuggers—that give developers deep insights into performance bottlenecks. Triton doesn't work with these tools. eDSLs by design are supposed to abstract out the details. As a result, when issues arise, developers cannot determine what the source of the issue was, they are often left guessing what the compiler did. This lack of observability makes performance debugging in Triton more challenging than in CUDA, despite its simpler programming model.
GPU Portability Without Performance Portability or Generality
GPU code written in Triton can run “pretty fast” if written for one specific GPU, but that code won’t go fast on different kinds of GPU’s—even across NVIDIA hardware. For example, Triton code optimized for A100 often performs poorly on H100 because newer architectures requires different code structures even to get to 80% performance—Triton doesn’t abstract things like pipelining and async memory transfers.

Moving to AMD GPUs is even worse. While Triton technically supports AMD hardware, performance and feature parity lag far behind NVIDIA, making cross-vendor portability impractical. The situation becomes catastrophic for non-GPU AI accelerators (e.g., TPUs, Groq chips, or Cerebras wafers). These architectures don’t follow the SIMT execution model that Triton assumes, leading to severely degraded performance, or requiring so many workarounds that the approach becomes counterproductive.
Ultimately, the promise of "write once, run anywhere" typically translates to: "Write once, run anywhere—but with significantly degraded performance on alternate platforms."
How does Triton stack up?
In our last two posts, we started building a wishlist for AI programming systems. Measuring against that, Triton has several big strengths and several challenges as well:
- "Provide a reference implementation": Triton provides a full implementation, not just a specification, with practical examples and tutorials. 👍
- "Have strong leadership and vision": Triton has defined leadership under OpenAI, but priorities align with OpenAI's needs rather than the broader community. Long-term governance remains a concern, especially for competing AI labs. 👍👎
- "Run with top performance on the industry leader's hardware": Triton runs well on NVIDIA hardware but typically with a ~20% performance gap compared to optimized CUDA. It struggles with the newest hardware features like FP8 and TMA. 👎
- "Evolve rapidly": Triton has adapted to some GenAI requirements but lags in supporting cutting-edge hardware features. Evolution speed depends on OpenAI's internal priorities rather than industry needs. 👎
- "Cultivate developer love": Triton provides a clean, Python-based programming model that many developers find intuitive and productive. Its integration with PyTorch 2.0 has expanded its reach. 👍👍👍
- "Build an open community": While open source, Triton's community is limited by OpenAI's control over the roadmap. Contributions from outside organizations face significant barriers. 👎
- "Avoid fragmentation": Triton itself is unified targeting NVIDIA GPUs 👍, but it is widely fragmented by other hardware vendors whose versions have different limitations and tradeoffs. 👎
- "Enable full programmability": Triton provides good programmability for standard operations 👍 but can't access/control all hardware features, particularly the newest accelerator capabilities. 👎
- "Provide leverage over AI complexity": Triton handles common patterns efficiently and it simplifies development 👍. It doesn’t support automatic fusion to solve the exponential complexity problem. 👎
- "Enable large scale applications": Triton focuses on single-device kernels and lacks built-in support for multi-GPU or multi-node scaling, but has great integration into PyTorch which takes care of that. 👍
Overall, it is clear that Triton is an extremely valuable part of the AI development ecosystem, particularly when targeting NVIDIA GPUs. That said, while Triton is the most well known eDSL due to its integration with PyTorch, other projects—like Pallas, CUTLASS Python, and cuTile—are exploring different trade-offs between productivity, performance, and hardware support. Each of these alternatives builds on similar ideas but takes a unique approach to tackling GPU programmability.
Other Python eDSLs: Pallas, CUTLASS Python, cuTile, etc.
Python eDSLs aren’t about delivering the best possible performance—they’re about making it easier for compiler developers to bring something to market. As a result, there are a lot of them—Triton is just the most well-known. Here are some I get asked about. (Disclaimer: I haven’t worked directly with these.)
Google Pallas
Google Pallas is a subproject of JAX, designed to enable custom ops—particularly for TPUs. It takes heavy inspiration from Triton but exposes more low-level compiler details rather than offering a high-level, user-friendly API.
From an outsider’s perspective, Pallas appears powerful but difficult to use, requiring deep knowledge of TPU hardware and compiler internals. Its own documentation highlights numerous footguns, making it clear that this is a tool for experts with low-level knowledge. As a result, adoption outside Google has been limited.
CUTLASS Python and cuTile
At GTC 2025, NVIDIA announced two new Python eDSLs: CUTLASS Python and cuTile. Neither are available for download yet, but here are some initial impressions:
- CUTLASS Python – Presented in this GTC talk, it looks heavily inspired by Google Pallas. It exposes low-level compiler details and requires deep hardware knowledge, without the tooling or debuggers that CUDA developers rely on. It’s launching on Blackwell first, and I doubt NVIDIA will open-source it or support other hardware vendors. I’m also curious to see how well Python’s lack of static typing works for writing low-level systems code like this.
- cuTile – This was widely reshared on X (example), but aside from a few slides, nothing is known about the availability dates or the technical details. It appears to be positioned as a proprietary Triton alternative. NVIDIA admits cuTile is approximately 15% slower than TRT-LLM. Given NVIDIA’s focus on peak performance, it’s unclear if it will use cuTile to build its own CUDA libraries. If it ships, real adoption inside NVIDIA will be the true test.
These eDSLs are just part of NVIDIA’s sprawling Python GPU ecosystem. At GTC 2025, NVIDIA said, “There is no one tool—you are going to pick the right tool for the job.” NVIDIA even had a session called “1,001 Ways to Write CUDA Kernels in Python”—just the thought of having to pick the right path sounds like a nightmare.

As a developer, I don’t think that dozens of options with subtle tradeoffs helps me. We need fewer tools that work better—not an ever-growing list of tradeoffs. NVIDIA is fragmenting its own developer ecosystem.
MLIR: A Unified Future for AI Compilers?
As I worked to scale Google TPUs in 2017 and 2018, a pattern emerged: first-generation AI frameworks like TensorFlow and PyTorch lacked scalability, while the second generation AI compilers like XLA sacrificed flexibility. To break this cycle, I led the team to build a new MLIR compiler framework—a modular, extensible compiler framework designed to support AI’s rapidly evolving hardware landscape.
Did it succeed? MLIR drove industry-wide breakthroughs—Python DSLs like Triton, cuTile, and others were built on top of it, redefining GPU programming. But like TVM and XLA before it, MLIR faces governance challenges, fragmentation, and competing corporate interests. The vision of a truly unified AI compiler stack still seems just out of reach, caught in the same power struggles that have shaped the industry for decades.
Tune in next time—we’ll dive into MLIR: the good, the bad… and the organizational dynamics.
—Chris


