

It seems like everyone has started talking about CUDA in the last year: It’s the backbone of deep learning, the reason novel hardware struggles to compete, and the core of NVIDIA’s moat and soaring market cap. With DeepSeek, we got a startling revelation: its breakthrough was made possible by “bypassing” CUDA, going directly to the PTX layer… but what does this actually mean? It feels like everyone wants to break past the lock-in, but we have to understand what we’re up against before we can formulate a plan.
CUDA’s dominance in AI is undeniable—but most people don’t fully understand what CUDA actually is. Some think it’s a programming language. Others call it a framework. Many assume it’s just “that thing NVIDIA uses to make GPUs faster.” None of these are entirely wrong—and many brilliant people are trying to explain this—but none capture the full scope of “The CUDA Platform.”
CUDA is not just one thing. It’s a huge, layered Platform—a collection of technologies, software libraries, and low-level optimizations that together form a massive parallel computing ecosystem. It includes:
- A low-level parallel programming model that allows developers to harness the raw power of GPUs with a C++-like syntax.
- A complex set of libraries and frameworks—middleware that powers crucial vertical use cases like AI (e.g., cuDNN for PyTorch and TensorFlow).
- A suite of high-level solutions like TensorRT-LLM and Triton, which enable AI workloads (e.g., LLM serving) without requiring deep CUDA expertise.
…and that’s just scratching the surface.
In this article, we’ll break down the key layers of the CUDA Platform, explore its historical evolution, and explain why it’s so integral to AI computing today. This sets the stage for the next part in our series, where we’ll dive into why CUDA has been so successful. Hint: it has a lot more to do with market incentives than it does the technology itself.
Let’s dive in. 🚀
The Road to CUDA: From Graphics to General-Purpose Compute
Before GPUs became the powerhouses of AI and scientific computing, they were graphics processors—specialized processors for rendering images. Early GPUs hardwired image rendering into silicon, meaning that every step of rendering (transformations, lighting, rasterization) was fixed. While efficient for graphics, these chips were inflexible—they couldn’t be repurposed for other types of computation.
Everything changed in 2001 when NVIDIA introduced the GeForce3, the first GPU with programmable shaders. This was a seismic shift in computing:
- 🎨 Before: Fixed-function GPUs could only apply pre-defined effects.
- 🖥️ After: Developers could write their own shader programs, unlocking programmable graphics pipelines.
This advancement came with Shader Model 1.0, allowing developers to write small, GPU-executed programs for vertex and pixel processing. NVIDIA saw where the future was heading: instead of just improving graphics performance, GPUs could become programmable parallel compute engines.
At the same time, it didn’t take long for researchers to ask:
“🤔 If GPUs can run small programs for graphics, could we use them for non-graphics tasks?”
One of the first serious attempts at this was the BrookGPU project at Stanford. Brook introduced a programming model that let CPUs offload compute tasks to the GPU—a key idea that set the stage for CUDA.
This move was strategic and transformative. Instead of treating compute as a side experiment, NVIDIA made it a first-class priority, embedding CUDA deeply into its hardware, software, and developer ecosystem.
The CUDA Parallel Programming Model
In 2006, NVIDIA launched CUDA (”Compute Unified Device Architecture”)—the first general-purpose programming platform for GPUs. The CUDA programming model is made up of two different things: the “CUDA programming language”, and the “NVIDIA Driver”.
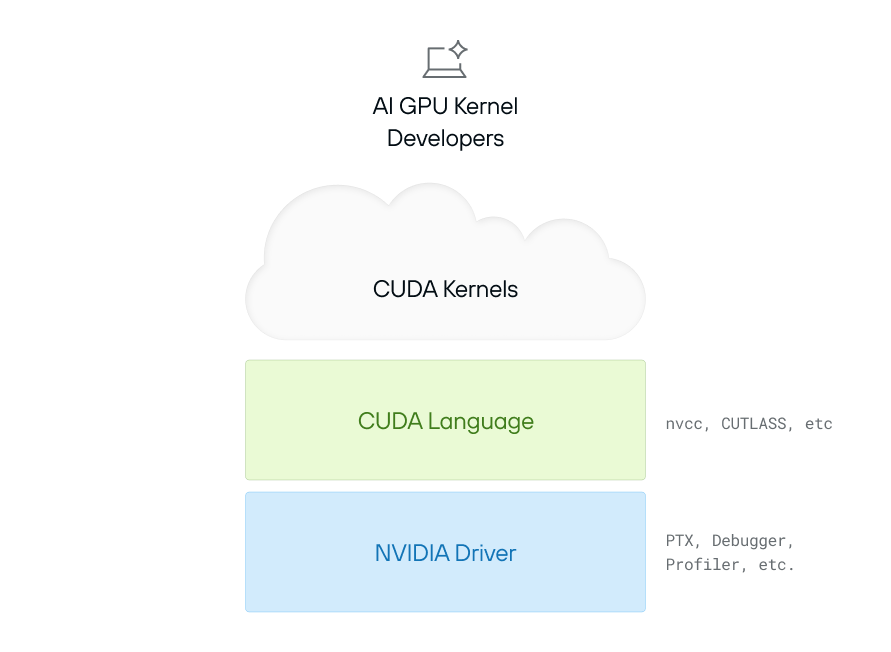
The CUDA language is derived from C++, with enhancements to directly expose low-level features of the GPU—e.g. its ideas of “GPU threads” and memory. A programmer can use this language to define a “CUDA Kernel”—an independent calculation that runs on the GPU. A very simple example is:
CUDA kernels allow programmers to define a custom computation that accesses local resources (like memory) and using the GPUs as very fast parallel compute units. This language is translated (”compiled”) down to “PTX”, which is an assembly language that is the lowest level supported interface to NVIDIA GPUs.
But how does a program actually execute code on a GPU? That’s where the NVIDIA Driver comes in. It acts as the bridge between the CPU and the GPU, handling memory allocation, data transfers, and kernel execution. A simple example is:
Note that all of this is very low level—full of fiddly details (e.g. pointers and “magic numbers”). If you get something wrong, you’re most often informed of this by a difficult to understand crash. Furthermore, CUDA exposes a lot of details that are specific to NVIDIA hardware—things like the “number of threads in a warp” (which we won't explore here).
Despite the challenges, these components enabled an entire generation of hardcore programmers to get access to the huge muscle that a GPU can apply to numeric problems. For example, the AlexNET ignited modern deep learning in 2012. It was made possible by custom CUDA kernels for AI operations like convolution, activations, pooling and normalization and the horsepower a GPU can provide.
While the CUDA language and driver are what most people typically think of when they hear “CUDA,” this is far from the whole enchilada—it’s just the filling inside. Over time, the CUDA Platform grew to include much more, and as it did, the meaning of the original acronym fell away from being a useful way to describe CUDA.
High-Level CUDA Libraries: Making GPU Programming More Accessible
The CUDA programming model opened the door to general-purpose GPU computing and is powerful, but it brings two challenges:
- CUDA is difficult to use, and even worse...
- CUDA doesn’t help with performance portability
Most kernels written for generation N will “keep working” on generation N+1, but often the performance is quite bad—far from the peak of what N+1 generation can deliver, even though GPUs are all about performance. This makes CUDA a strong tool for expert engineers, but a steep learning curve for most developers. But is also means that significant rewrites are required every time a new generation of GPU comes out (e.g. Blackwell is now emerging).
As NVIDIA grew it wanted GPUs to be useful to people who were domain experts in their own problem spaces, but weren’t themselves GPU experts. NVIDIA’s solution to this problem was to start building rich and complicated closed-source, high-level libraries that abstract away low-level CUDA details. These include:
- cuDNN (2014) – Accelerates deep learning (e.g., convolutions, activation functions).
- cuBLAS – Optimized linear algebra routines.
- cuFFT – Fast Fourier Transforms (FFT) on GPUs.
- … and many others.
With these libraries, developers could tap into CUDA’s power without needing to write custom GPU code, with NVIDIA taking on the burden of rewriting these for every generation of hardware. This was a big investment from NVIDIA, but it worked.
The cuDNN library is especially important in this story—it paved the way for Google’s TensorFlow (2015) and Meta’s PyTorch (2016), enabling deep learning frameworks to take off. While there were earlier AI frameworks, these were the first frameworks to truly scale—modern AI frameworks now have thousands of these CUDA kernels and each is very difficult to write. As AI research exploded, NVIDIA aggressively pushed to expand these libraries to cover the important new use-cases.

NVIDIA’s investment into these powerful GPU libraries enabled the world to focus on building high-level AI frameworks like PyTorch and developer ecosystems like HuggingFace. Their next step was to make entire solutions that could be used out of the box—without needing to understand the CUDA programming model at all.
Fully vertical solutions to ease the rapid growth of AI and GenAI
The AI boom went far beyond research labs—AI is now everywhere. From image generation to chatbots, from scientific discovery to code assistants, Generative AI (GenAI) has exploded across industries, bringing a flood of new applications and developers into the field.
At the same time, a new wave of AI developers emerged, with very different needs. In the early days, deep learning required highly specialized engineers who understood CUDA, HPC, and low-level GPU programming. Now, a new breed of developer—often called AI engineers—is building and deploying AI models without needing to touch low-level GPU code.
To meet this demand, NVIDIA went beyond just providing libraries—it now offers turnkey solutions that abstract away everything under the hood. Instead of requiring deep CUDA expertise, these frameworks allow AI developers to optimize and deploy models with minimal effort.
- Triton Serving – A high-performance serving system for AI models, allowing teams to efficiently run inference across multiple GPUs and CPUs.
- TensorRT – A deep learning inference optimizer that automatically tunes models to run efficiently on NVIDIA hardware.
- TensorRT-LLM – An even more specialized solution, built for large language model (LLM) inference at scale.
- … plus many (many) other things.

These tools completely shield AI engineers from CUDA’s low-level complexity, letting them focus on AI models and applications, not hardware details. These systems provide significant leverage which has enabled the horizontal scale of AI applications.
The “CUDA Platform” as a whole
CUDA is often thought of as a programming model, a set of libraries, or even just "that thing NVIDIA GPUs run AI on." But in reality, CUDA is much more than that—it is a unifying brand, a truly vast collection of software, and a highly tuned ecosystem, all deeply integrated with NVIDIA’s hardware. For this reason, the term “CUDA” is ambiguous—we prefer the term “The CUDA Platform” to clarify that we’re talking about something closer in spirit to the Java ecosystem, or even an operating system, than merely a programming language and runtime library.
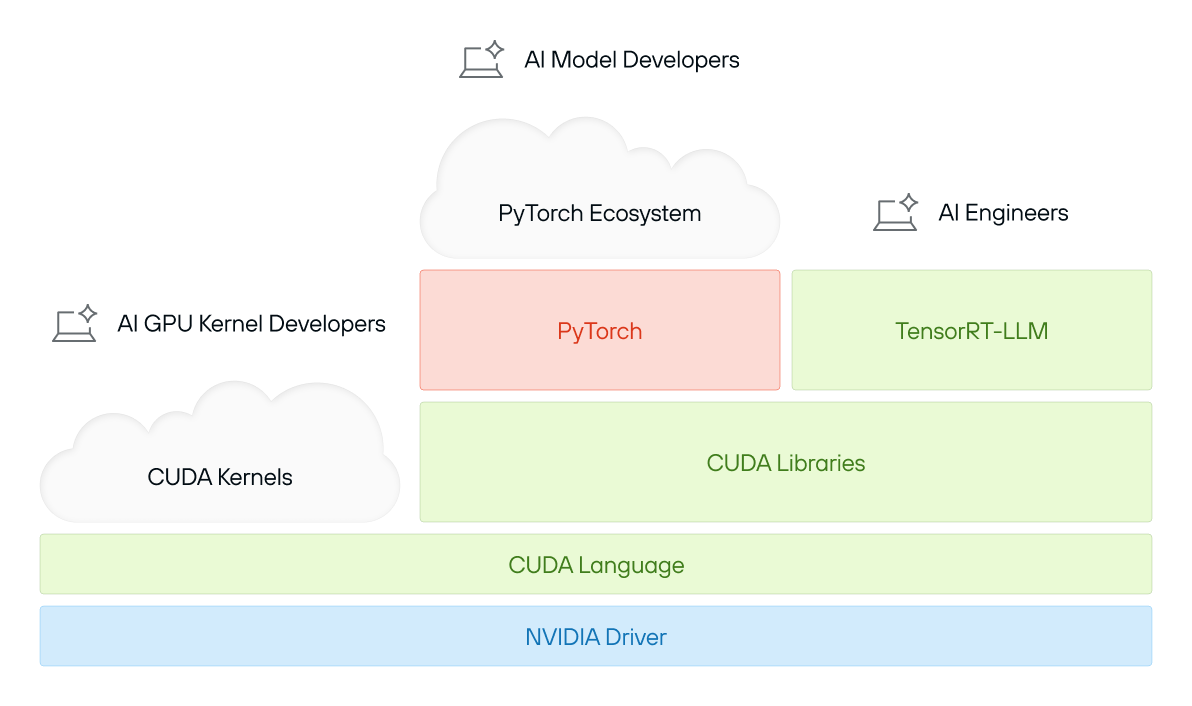
At its core, the CUDA Platform consists of:
- A massive codebase – Decades of optimized GPU software, spanning everything from matrix operations to AI inference.
- A vast ecosystem of tools & libraries – From cuDNN for deep learning to TensorRT for inference, CUDA covers an enormous range of workloads.
- Hardware-tuned performance – Every CUDA release is deeply optimized for NVIDIA’s latest GPU architectures, ensuring top-tier efficiency.
- Proprietary and opaque – When developers interact with CUDA’s library APIs, much of what happens under the hood is closed-source and deeply tied to NVIDIA’s ecosystem.
CUDA is a powerful but sprawling set of technologies—an entire software platform that sits at the foundation of modern GPU computing, even going beyond AI specifically.
Now that we know what “CUDA” is, we need to understand how it got to be so successful. Here’s a hint: CUDA’s success isn’t really about performance—it’s about strategy, ecosystem, and momentum. In the next post, we’ll explore what enabled NVIDIA’s CUDA software to shape and entrench the modern AI era.
See you next time. 🚀
-Chris
What’s next?
Learn more about the MAX Platform and the Mojo programming language, and join us in building the next wave of AI innovation.
- Get started with MAX–explore our latest platform to accelerate your AI work.
- Check out the the Mojo manual and get started with our next-generation language for programming GPUs.
- Continue the conversation in the Modular forum.


