

In the early days of AI hardware, writing high-performance GPU code was a manageable—if tedious—task. Engineers could handcraft CUDA kernels in C++ for the key operations they needed, and NVIDIA could build these into libraries like cuDNN to drive their lock-in. But as deep learning advanced, this approach completely broke down.
Neural networks grew bigger, architectures became more sophisticated, and researchers demanded ever-faster iteration cycles. The number of unique operators in frameworks like PyTorch exploded—now numbering in the thousands. Manually writing and optimizing each one for every new hardware target? Impossible.
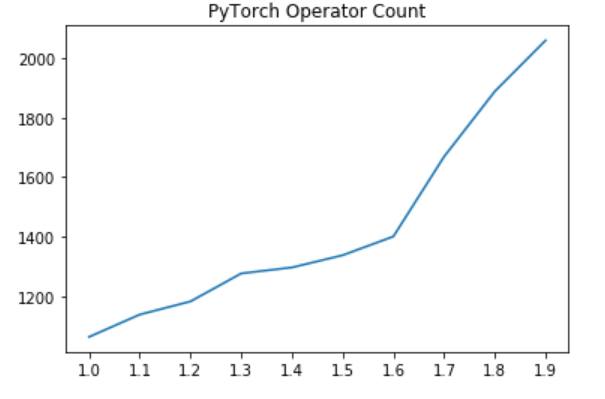
This challenge forced a fundamental shift: instead of writing kernels by hand, what if we had a compiler that could generate them automatically? AI compilers emerged to solve this exact problem, marking a transformation from human-crafted CUDA to machine-generated, hardware-optimized compute.
But as history has shown, building a successful compiler stack isn’t just a technical challenge—it’s a battle over ecosystems, fragmentation, and control. So what worked? What didn’t? And what can we learn from projects like TVM and OpenXLA?
Let’s dive in. 🚀
What is an “AI Compiler”?
At its core, an AI compiler is a system that takes high-level operations—like those in PyTorch or TensorFlow—and automatically transforms them into highly efficient GPU code. One of the most fundamental optimizations it performs is called “kernel fusion.” To see why this matters, let’s consider a simple example: multiplying two matrices (”matmul”) and then applying a ReLU (Rectified Linear Unit) activation function. These are simple but important operations that occur in common neural networks.
Naïve approach: Two separate kernels
The most straightforward (but inefficient) way to do this is to perform matrix multiplication first, store the result in memory, then load it again to apply ReLU.
These operations are extremely familiar to engineers that might write a CUDA kernel (though remember that CUDA uses unwieldy C++ syntax!), and there are many tricks used for efficient implementation.
While the above approach is simple and modular, executing operations like this is extremely slow because it writes the entire matrix C to memory after matmul(), then reads it back again in relu(). This memory traffic dominates performance, especially on GPUs, where memory access is more expensive than local compute.
Fused kernel: One pass, no extra memory traffic
The solution for this is simple: we can “fuse” these two operations into a single kernel, eliminating redundant memory access. Instead of storing C after matmul(), we apply relu() immediately inside the same loop:
While the benefit of this transformation varies by hardware and matrix size, the results can be profound: sometimes 2x better performance! Why is this the case? By fusing the operations:
✅ We eliminate an extra memory write/read, reducing pressure on memory bandwidth.
✅ We keep data in registers or shared memory, avoiding slow global memory access.
✅ We reduce memory usage and allocation/deallocation overhead, since the intermediate buffer has been removed.
This is the simplest example of kernel fusion: There are many more powerful transformations, and AI kernel engineers have always pushed the limits of optimization (learn more). With GenAI driving up compute demand, these optimizations are more critical than ever.
Great performance, but an exponential complexity explosion!
While these sorts of optimizations can be extremely exciting and fun to implement for those who are chasing low cost and state of the art performance, there is a hidden truth: this approach doesn’t scale.
Modern machine learning toolkits include hundreds of different “operations” like matmul, convolution, add, subtract, divide, etc., as well as dozens of activation functions beyond ReLU. Each neural network needs them to be combined in different ways: this causes an explosion in the number of permutations that need to be implemented (hundreds of operations x hundreds of operations = too many to count). NVIDIA’s libraries like cuDNN provide a fixed list of options to choose from, without generality to new research.
Furthermore, there are other axes of explosion as well: we’ve seen an explosion of new numerics datatypes (e.g. “float8”), and of course, there is also an explosion of the kind of hardware that AI should support.
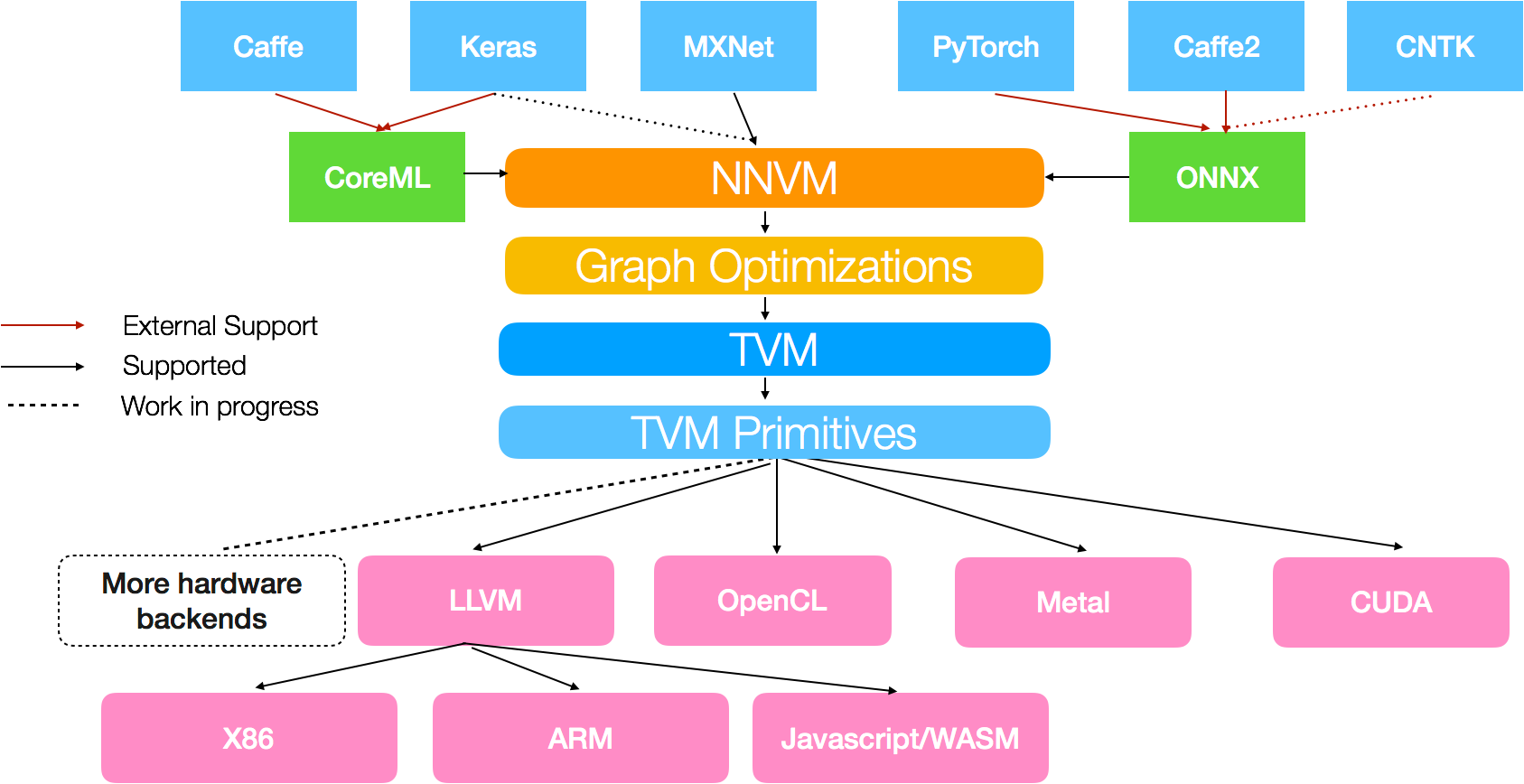
Early AI compilers: TVM
There are many AI compilers, but one of the earliest and most successful is TVM - the “Tensor Virtual Machine”. This system took models from TensorFlow/PyTorch and optimized them for diverse hardware, i.e. by applying kernel fusion automatically. This project started at the University of Washington by Tianqi Chen and Professor Luis Ceze in about 2016, and delivered a number of innovative results and performance wins described in the 2018 paper that outlines the TVM architecture. It was open sourced and incorporated into the Apache project.
Across its journey, TVM has been adopted by hardware makers (including public contributions from companies like ARM, Qualcomm, Facebook, Intel, and many others) across embedded, DSP, and many other applications. TVM's core contributors later founded OctoAI, which NVIDIA acquired in late 2024—giving it control over many of the original TVM developers and, potentially, the project's future.
TVM is an important step for the AI compiler industry, but what can we learn from it? Here are my key takeaways. Disclaimer: although TVM was a user of LLVM and I had great interest in it, I was never directly involved. This is my perspective as an outsider.
Wasn’t able to deliver performance on modern hardware
TVM struggled to deliver peak performance on modern AI hardware, particularly as GPUs evolved toward TensorCores and other specialized acceleration. It added support over time but was often late and failed to fully unlock performance. As such, it suffered from one of the same problems as OpenCL: You can’t deliver performance if you can’t unlock the hardware.
Fragmentation driven by conflicting commercial interests
Unlike OpenCL, TVM wasn't just a specification—it was an actual implementation. This made it far more useful out of the box and attracted hardware vendors. But fragmentation still reared its head: vendors forked the code, made incompatible changes, and struggled to stay in sync, slowing progress. This led to friction executing architectural changes (because downstream vendors complained about their forks being broken), which slowed development.
Agility is required to keep up with rapid AI advances
A final challenge is that TVM was quite early, but the pace of AI innovation around it was rapid. TensorFlow and PyTorch rapidly evolved due to backing by huge companies like Google, Meta, and NVIDIA, improving their performance and changing the baselines that TVM compared against. The final nail in the coffin, though, was GenAI, which changed the game. TVM was designed for “TradAI”: a set of relatively simple operators that needed fusion, but GenAI has large and complex algorithms deeply integrated with the hardware—things like FlashAttention3. TVM fell progressively behind as the industry evolved.
Less strategically important (but still material), TVM also has technical problems, e.g. really slow compile times due to excessive auto-tuning. All of these together contributed to project activity slowing.
Today, NVIDIA now employs many of its original leaders, leaving its future uncertain. Meanwhile, Google pursued its own vision with OpenXLA...
The XLA compiler from Google: Two different systems under one name
Unlike TVM, which started as an academic project, XLA was built within Google—one of the most advanced AI companies, with deep pockets and a vested interest in AI hardware. Google developed XLA to replace CUDA for its (now successful) TPU hardware, ensuring tight integration and peak performance for its own AI workloads. I joined Google Brain in 2017 to help scale TPUs (and XLA) from an experimental project into the world's second-most successful AI accelerator (behind NVIDIA).

Google had hundreds of engineers working on XLA (depending on how you count), and it evolved rapidly. Google added CPU and GPU support, and eventually formed the OpenXLA foundation. XLA is used as the AI compiler foundation for several important hardware projects, including AWS Inferentia/Trainium among others.
Beyond code generation, one of the biggest achievements and contributions of XLA is its ability to handle large scale machine learning models. At extreme scale, the ability to train with many thousands of chips becomes essential. Today, the largest practical models are starting to require advanced techniques to partition them across multiple machines—XLA developed clean and simple approaches that enable this.
Given all this investment, why don’t leading projects like PyTorch and vLLM run GPUs with XLA? The answer is that XLA is two different projects with a conflated brand, incentive structure challenges for their engineers, governance struggles, and technical problems that make it impractical.
Google uses XLA-TPU, but OpenXLA is for everyone else
The most important thing to understand is that XLA exists in two forms: 1) the internal, closed source XLA-TPU compiler that powers Google’s AI infrastructure, and 2) OpenXLA, the public project for CPUs and GPUs. These two share some code (“StableHLO”) but the vast majority of the code (and corresponding engineering effort) in XLA is Google TPU specific—closed and proprietary, and not used on CPUs or GPUs. XLA on GPU today typically calls into standard CUDA libraries to get performance. 🤷
This leads to significant incentive structure problems—Google engineers might want to build a great general-purpose AI compiler, but their paychecks are tied to making TPUs go brrr. Leadership has little incentive to optimize XLA for GPUs or alternative hardware—it’s all about keeping TPUs competitive. In my experience, XLA has never prioritized a design change that benefits other chips if it risks TPU performance.
The result? A compiler that works great for TPUs but falls short elsewhere.
Governance of OpenXLA
XLA was released early as an open source but explicitly Google-controlled project. Google’s early leadership in AI with TensorFlow got it adopted by other teams around the industry. In March 2023, the project was renamed to OpenXLA with an announcement about independence.
Despite this rebranding, Google still controls OpenXLA (seen in its governance structure), and doesn’t seem to be investing: there are declining community contributions, and the OpenXLA X account has been inactive since 2023.
Technical challenges with XLA
Like TVM, XLA was designed around a fixed set of predefined operators (StableHLO). This approach worked well for traditional AI models like ResNet-50 in 2017, but struggles with modern GenAI workloads, which require more flexibility in datatypes, custom kernels, and hardware-specific optimizations. This is a critical problem today, when modern GenAI algorithms require innovation in datatypes (see the chart below), or as DeepSeek showed us, at the hardware level and in novel communication strategies.
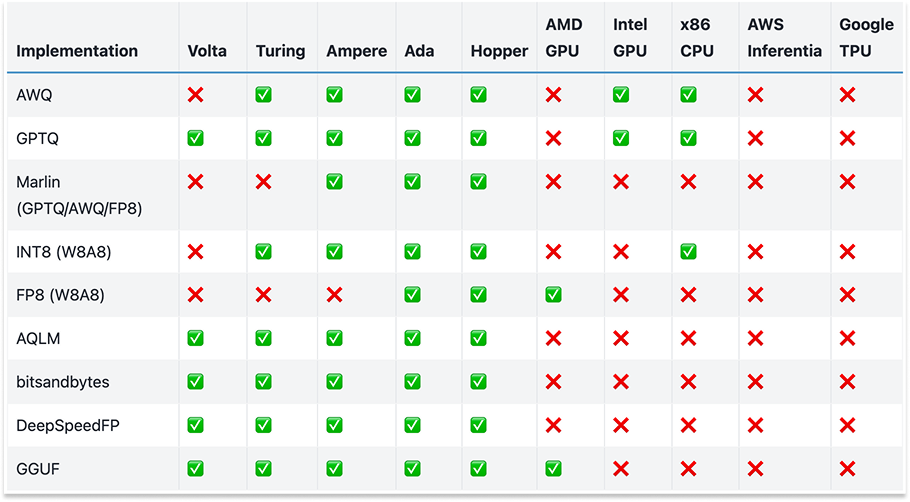
As a consequence, XLA (like TVM) suffers from being left behind by GenAI: today much of the critical workloads are written in experimental systems like Pallas that bypass the XLA compiler, even on TPUs. The core reason is that in its efforts to simplify AI compilation, XLA abstracted away too much of the hardware. This worked for early AI models, but GenAI demands fine-grained control over accelerators—something XLA simply wasn’t built to provide. And so, just like TVM, it’s being left behind.
Lessons learned from TVM and XLA
I take pride in the technical accomplishments we proved in XLA-TPU: XLA supported many generational research breakthroughs, including the invention of the transformer, countless model architectures, and research and product scaling that isn’t seen anywhere else. It is clearly the most successful non-NVIDIA training and inference hardware that exists, and powers Google’s (many) leading AI products and technologies. Though I know less about it, I have a lot of respect for TVM’s contribution to compiler research, autotuning and powering many early AI systems.
That said, there is a lot to learn from both projects together. Going down the list of lessons learned from OpenCL:
- “Provide a reference implementation”: They both provide a useful implementation, not just a technical specification like OpenCL. 👍
- “Have strong leadership and vision”: They have defined leadership teams and a vision behind them 👍. However, OpenXLA’s vision isn’t aligned with hardware teams that want to adopt it. And like many Google projects, its long-term prospects are uncertain, making it risky to depend on. 👎
- “Run with top performance on the industry leader’s hardware”: Neither XLA nor TVM could fully unlock NVIDIA GPUs without calling into CUDA libraries, and thus it is unclear whether they are “good” on other AI accelerators without similar libraries to call into. 👎 XLA on TPUs does show the power of TPU hardware and its greater scalability than NVIDIA hardware. 👍
- “Evolve rapidly”: Both projects were built for traditional deep learning, but GenAI shattered their assumptions. The shift to massive models, complex memory hierarchies, and novel attention mechanisms required a new level of hardware-software co-design that they weren’t equipped to handle. 👎 This ultimately made both projects a lot less interesting to folks who might want to use them on modern hardware that is expected to support GenAI. 👎👎
- “Cultivate developer love”: In its strong spot, XLA provided a simple and clean model that people could understand, one that led to the rise of the JAX framework among others. 👍👍 TVM had cool technology but wasn’t a joy to use with long compile times and incompatibility with popular AI models. 👎
- “Build an open community”: TVM built an open community, and OpenXLA aimed to. Both benefited from industry adoption as a result. 👍
- “Avoid fragmentation”: Neither project did–TVM was widely forked and changed downstream, and XLA never accepted support for non-CPU/GPU hardware in its tree; all supported hardware was downstream. 👎
The pros and cons of AI compiler technology
First-generation AI frameworks like TensorFlow and PyTorch 1.0 relied heavily on hand-written CUDA kernels, which couldn’t scale to rapidly evolving AI workloads. TVM and XLA, as second-generation approaches, tackled this problem with automated compilation. However, in doing so, they sacrificed key strengths of the first generation: extensibility for custom algorithms, fine-grained control over hardware, and dynamic execution—features that turned out to be critical for GenAI.
Beyond what we learned from OpenCL, we can also add a few wishlist items:
- Enable full programmability: We can’t democratize AI if we hide the power of any given chip from the developer. If you spend $100M on a cluster of one specific kind of GPU, you’ll want to unlock the full power of that silicon without being limited to a simplified interface.
- Provide leverage over AI complexity: The major benefit of AI compilers is that it allows one to scale into the exponential complexity of AI (operators, datatypes, etc) without having to manually write a ton of code. This is essential to unlock next generation research.
- Enable large scale applications: The transformative capability of XLA is the ability to easily scale to multiple accelerators and nodes. This capability is required to support the largest and most innovative models with ease. This is something that CUDA never really cracked.
Despite the wins and losses of these AI compilers, neither could fully unlock GPU performance or democratize AI compute. Instead, they reinforced silos: XLA remained TPU-centric, while TVM splintered into incompatible vendor-specific forks. They failed in the exact way CUDA alternatives were supposed to succeed!
Maybe the Triton “language” will save us?
But while these compilers struggled, a different approach was taking shape. Instead of trying to replace CUDA, it aimed to embrace GPU programming—while making it more programmable.
Enter Triton and the new wave of Python eDSLs—an attempt to bridge the gap between CUDA’s raw power and Python’s ease of use. In the next post, we’ll dive into these frameworks to see what they got right, where they fell short, and whether they finally broke free from the mistakes of the past.
Of course, you already know the answer. The CUDA Empire still reigns supreme. But why? And more importantly—what can we do about it?
Those who cannot remember the past are condemned to repeat it.
—George Santayana
Perhaps one day, compiler technology will alleviate our suffering without taking away our power. Until next time, 🚀
—Chris


