

If we as an ecosystem hope to make progress, we need to understand how the CUDA software empire became so dominant. On paper, alternatives exist—AMD’s ROCm, Intel’s oneAPI, SYCL-based frameworks—but in practice, CUDA remains the undisputed king of GPU compute.
How did this happen?
The answer isn’t just about technical excellence—though that plays a role. CUDA is a developer platform built through brilliant execution, deep strategic investment, continuity, ecosystem lock-in, and, of course, a little bit of luck.
This post breaks down why CUDA has been so successful, exploring the layers of NVIDIA’s strategy—from its early bets on generalizing parallel compute to the tight coupling of AI frameworks like PyTorch and TensorFlow. Ultimately, CUDA’s dominance is not just a triumph of software but a masterclass in long-term platform thinking.
Let’s dive in. 🚀
The Early Growth of CUDA
A key challenge of building a compute platform is attracting developers to learn and invest in it, and it is hard to gain momentum if you can only target niche hardware. In a great “Acquired” podcast, Jensen Huang shares that a key early NVIDIA strategy was to keep their GPUs compatible across generations. This enabled NVIDIA to leverage its install base of already widespread gaming GPUs, which were sold for running DirectX-based PC games. Furthermore, it enabled developers to learn CUDA on low-priced desktop PCs and scale into more powerful hardware that commanded high prices.
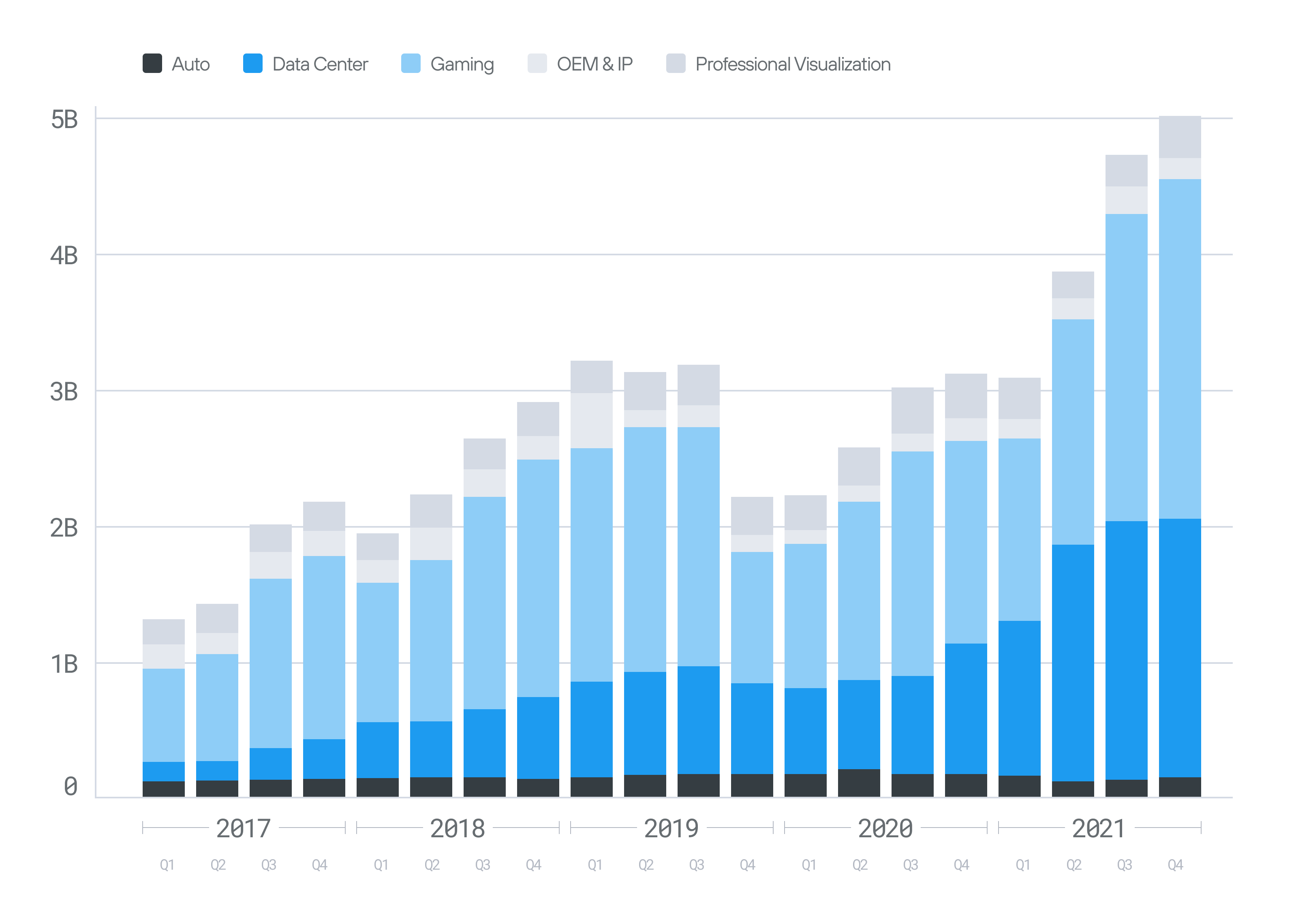
This might seem obvious now, but at the time it was a bold bet: instead of creating separate product lines optimized for different use-cases (laptops, desktops, IoT, datacenter, etc.), NVIDIA built a single contiguous GPU product line. This meant accepting trade-offs—such as power or cost inefficiencies—but in return, it created a unified ecosystem where every developer’s investment in CUDA could scale seamlessly from gaming GPUs to high-performance datacenter accelerators. This strategy is quite analogous to how Apple maintains and drives its iPhone product line forward.
The benefits of this approach were twofold:
- Lowering Barriers to Entry – Developers could learn CUDA using the GPUs they already had, making it easy to experiment and adopt.
- Creating a Network Effect – As more developers started using CUDA, more software and libraries were created, making the platform even more valuable.
This early install base allowed CUDA to grow beyond gaming into scientific computing, finance, AI, and high-performance computing (HPC). Once CUDA gained traction in these fields, its advantages over alternatives became clear: NVIDIA’s continued investment ensured that CUDA was always at the cutting edge of GPU performance, while competitors struggled to build a comparable ecosystem.
Catching and Riding the Wave of AI Software
CUDA’s dominance was cemented with the explosion of deep learning. In 2012, AlexNet, the neural network that kickstarted the modern AI revolution, was trained using two NVIDIA GeForce GTX 580 GPUs. This breakthrough not only demonstrated that GPUs were faster at deep learning—it proved they were essential for AI progress and led to CUDA’s rapid adoption as the default compute backend for deep learning.
As deep learning frameworks emerged—most notably TensorFlow (Google, 2015) and PyTorch (Meta, 2016)—NVIDIA seized the opportunity and invested heavily in optimizing its High-Level CUDA Libraries to ensure these frameworks ran as efficiently as possible on its hardware. Rather than leaving AI framework teams to handle low-level CUDA performance tuning themselves, NVIDIA took on the burden by aggressively refining cuDNN and TensorRT as we discussed in Part 2.
This move not only made PyTorch and TensorFlow significantly faster on NVIDIA GPUs—it also allowed NVIDIA to tightly integrate its hardware and software (a process known as “hardware/software co-design”) because it reduced coordination with Google and Meta. Each major new generation of hardware would come out with a new version of CUDA that exploited the new capabilities of the hardware. The AI community, eager for speed and efficiency, was more than willing to delegate this responsibility to NVIDIA—which directly led to these frameworks being tied to NVIDIA hardware.
But why did Google and Meta let this happen? The reality is that Google and Meta weren’t singularly focused on building a broad AI hardware ecosystem—they were focused on using AI to drive revenue, improve their products, and unlock new research. Their top engineers prioritized high-impact internal projects to move internal company metrics. For example, these companies decided to build their own proprietary TPU chips—pouring their effort into optimizing for their own first-party hardware. It made sense to give the reins to NVIDIA for GPUs.
Makers of alternative hardware faced an uphill battle—trying to replicate the vast, ever-expanding NVIDIA CUDA library ecosystem without the same level of consolidated hardware focus. Rival hardware vendors weren’t just struggling—they were trapped in an endless cycle, always chasing the next AI advancement on NVIDIA hardware. This impacted Google and Meta’s in-house chip projects as well, which led to numerous projects, including XLA and PyTorch 2. We can dive into these deeper in subsequent articles, but despite some hopes, we can see today that nothing has enabled hardware innovators to match the capabilities of the CUDA platform.
With each generation of its hardware, NVIDIA widened the gap. Then suddenly, in late 2022, ChatGPT exploded onto the scene, and with it, GenAI and GPU compute went mainstream.
Capitalizing on the Generative AI Surge
Almost overnight, demand for AI compute skyrocketed—it became the foundation for billion-dollar industries, consumer applications, and competitive corporate strategy. Big tech and venture capital firms poured billions into AI research startups and CapEx buildouts—money that ultimately funneled straight to NVIDIA, the only player capable of meeting the exploding demand for compute.
As demand for AI compute surged, companies faced a stark reality: training and deploying GenAI models is incredibly expensive. Every efficiency gain—no matter how small—translated into massive savings at scale. With NVIDIA’s hardware already entrenched in data centers, AI companies faced a serious choice: optimize for CUDA or fall behind. Almost overnight, the industry pivoted to writing CUDA-specific code. The result? AI breakthroughs are no longer driven purely by models and algorithms—they now hinge on the ability to extract every last drop of efficiency from CUDA-optimized code.
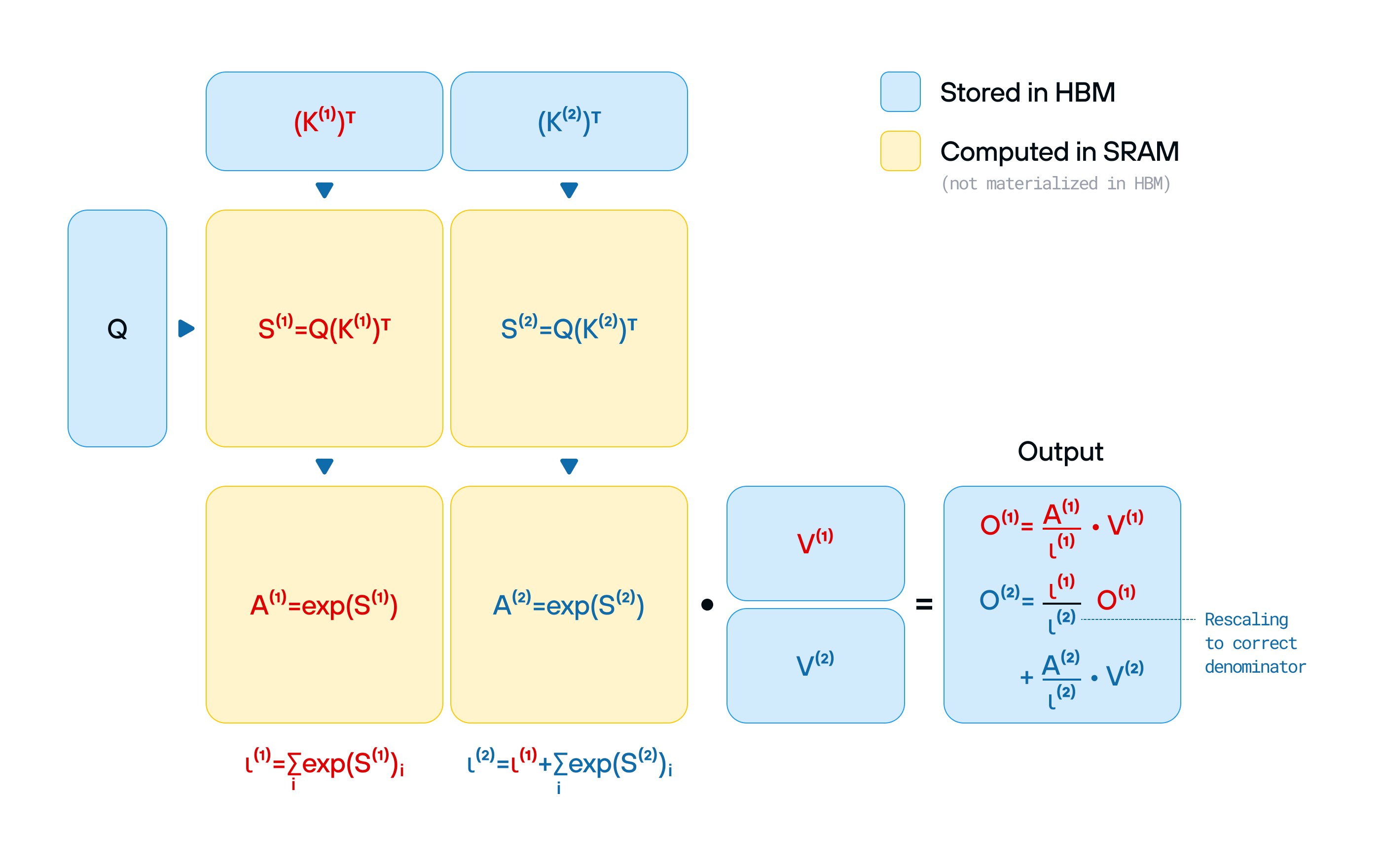
Take FlashAttention-3, for example: this cutting-edge optimization slashed the cost of running transformer models—but it was built exclusively for Hopper GPUs, reinforcing NVIDIA’s lock-in by ensuring the best performance was only available on its latest hardware. Continuous research innovations followed the same trajectory, for example when DeepSeek went directly to PTX assembly, gaining full control over the hardware at the lowest possible level. With the new NVIDIA Blackwell architecture on the horizon, we can look forward to the industry rewriting everything from scratch again.
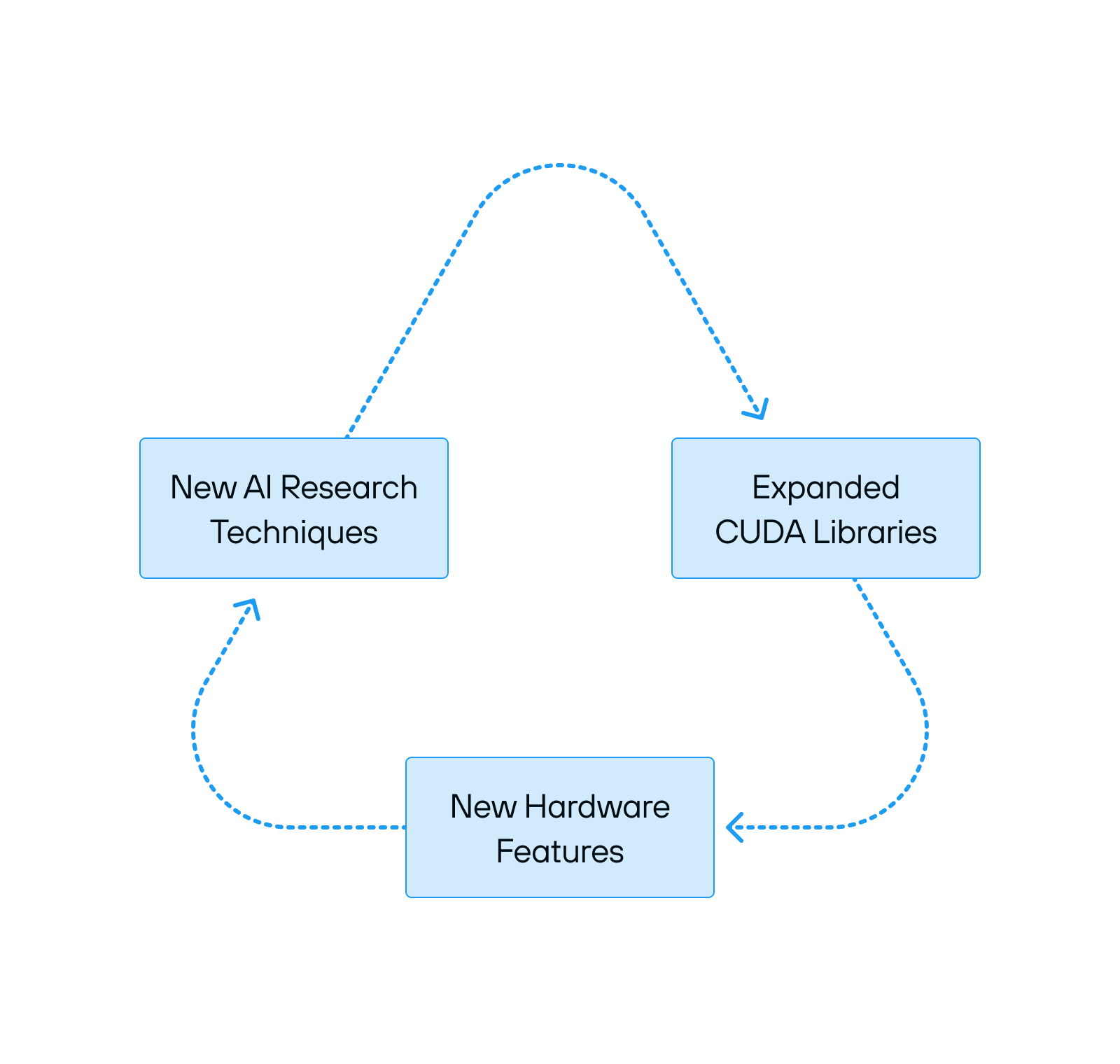
The Reinforcing Cycles That Power CUDA’s Grip
This system is accelerating and self-reinforcing. Generative AI has become a runaway force, driving an insatiable demand for compute, and NVIDIA holds all the cards. The biggest install base ensures that most AI research happens in CUDA, which in turn drives investment into optimizing NVIDIA’s platform.
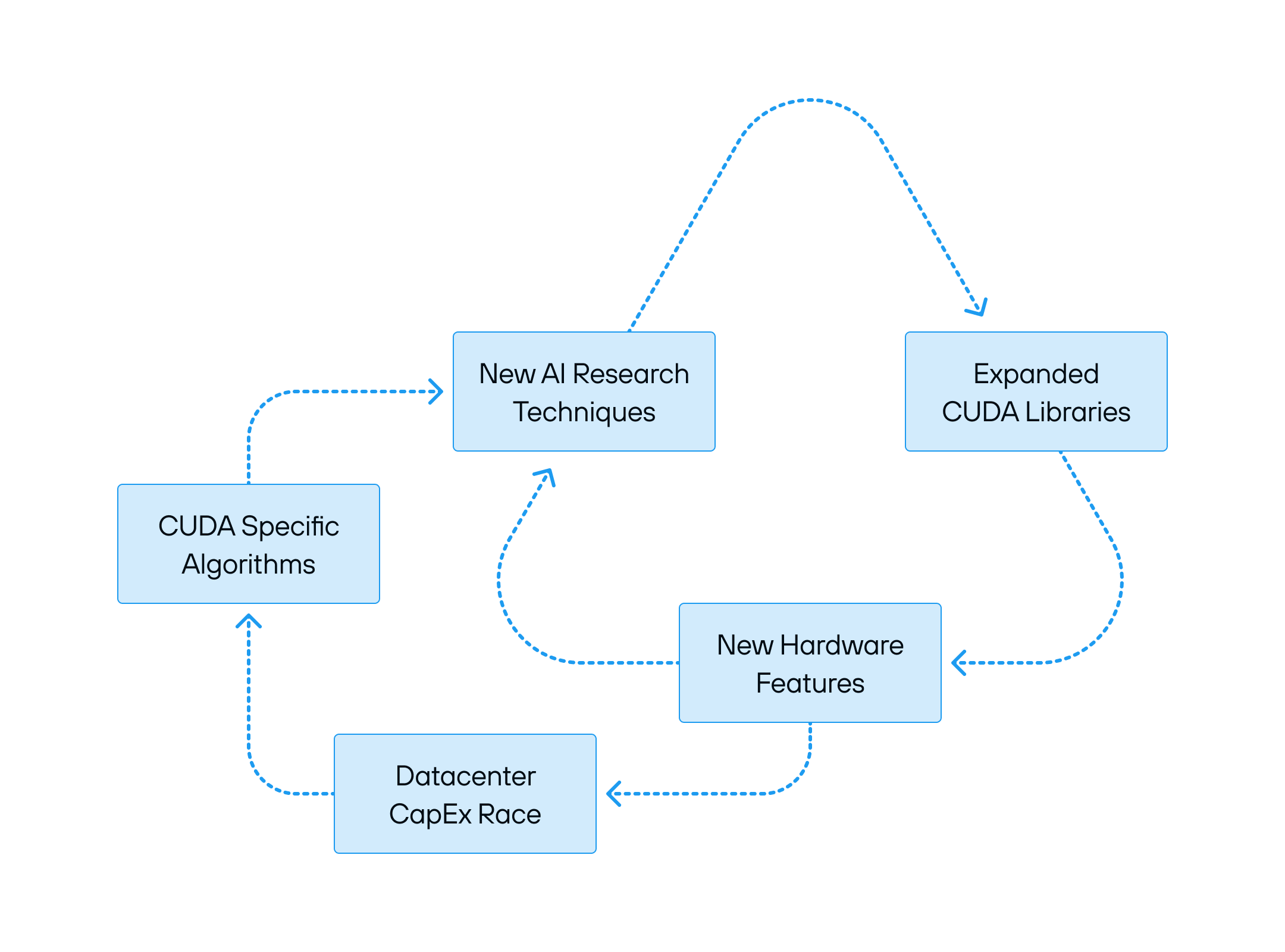
Every new generation of NVIDIA hardware brings new features and new efficiencies, but it also demands new software rewrites, new optimizations, and deeper reliance on NVIDIA’s stack. The future seems inevitable: a world where CUDA’s grip on AI compute only tightens.
Except CUDA isn't perfect.
The same forces that entrench CUDA’s dominance are also becoming a bottleneck—technical challenges, inefficiencies, and barriers to broader innovation. Does this dominance actually serve the AI research community? Is CUDA good for developers, or just good for NVIDIA?
Let’s take a step back: We looked at what CUDA is and why it is so successful, but is it actually good? We’ll explore this in Part 4—stay tuned and let us know if you find this series useful, or have suggestions/requests! 🚀
-Chris


