🎉 FIRST 50 CUSTOMERS PROMO
Batch Inference that is 85% cheaper and more accurate than anywhere else.
🎉
Get 1 billion tokens FREE
Choose a time that works for you to secure your free tokens. You can be up and running immediately after the call, as long as it's a model we support.
View pricing
Schedule a call now
We've recieved your details, but let's talk through your request and launch it immediately.
Schedule Call
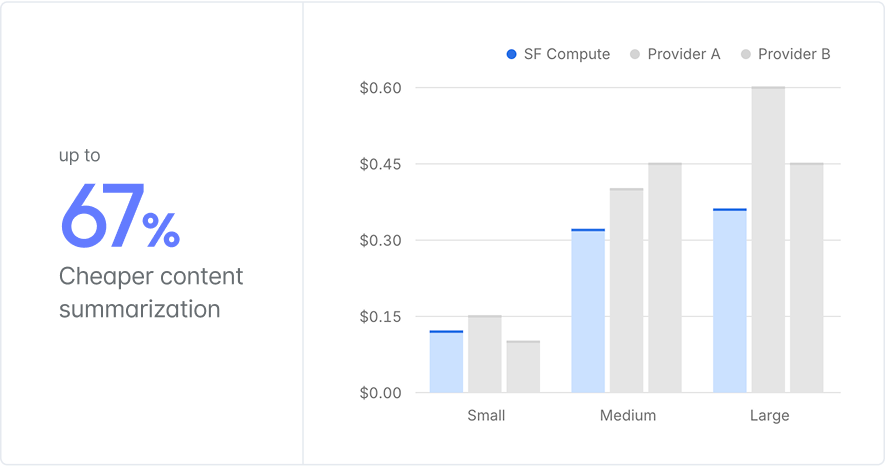
The best available pricing
Unlike other providers, inference prices are market-based. The token price tracks the underlying market-based compute cost on SFC & current load. In other words, we give you the best available price.
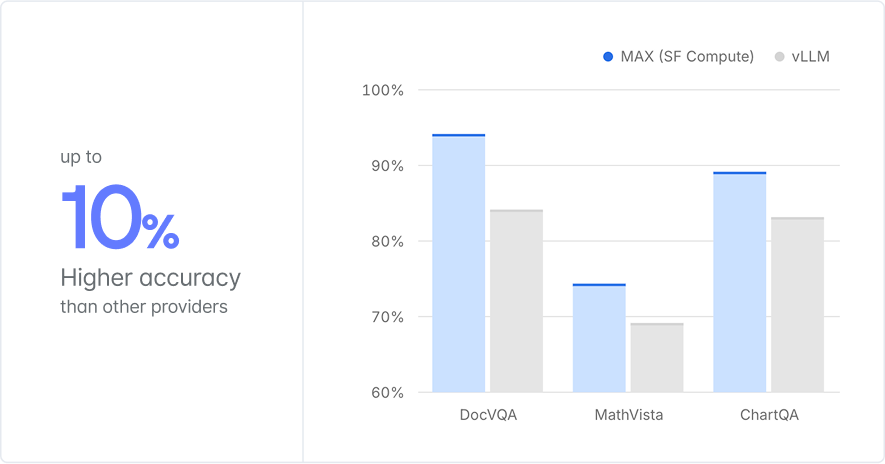
The best available accuracy
Our MAX inference engine consistently outperforms other providers across key benchmarks like DocVQA, MathVista, and ChartQA on accuracy. We save you money and get you more accurate results while we do it.
Built for trillion-token, sensitive, multimodal use cases
LSI natively supports very large scale batch inference, with far higher rate limits & throughput than other providers. Unlike other services, we don't force you to upload petabytes of data to us. Our batch inference reads & writes to an S3-compatible object store, so your sensitive data isn't stored indefinitely on our servers. LSI natively handles multimodal use cases without forcing you to publicly share links to your content.
Bespoke enterprise support
LSI is designed for large scale, mostly enterprise, use cases. That lets us be more hands on than traditional, self-serve providers.
Want a deployment behind your private network?
Need to hit specific latency, throughput, or uptime requirements?
Is there a model that's performing better in your evals, but we're not serving it?
Between Modular's world-class engineering & SFC's dramatic price optimization, we'll work with you to get the best possible price & performance.
Supported models
We currently support the following models below the cost of every current provider on average. Exact prices, latency, and throughput depend on the use case & current market conditions. For a technical demo, get a quote.
| Model | Hugging Face Name | Size | Price 1M Tokens |
|---|---|---|---|
|
gpt‑oss‑120b
New
|
openai/gpt-oss-120b | 120B | $0.04 input $0.20 output |
|
gpt‑oss‑20b
New
|
openai/gpt-oss-20b | 20B | $0.02 input $0.08 output |
|
Llama‑3.1‑405B‑Instruct
|
meta-llama/Llama-3.1-405B-Instruct | 405B | $0.50 input $1.50 output |
|
Llama‑3.3‑70B‑Instruct
|
meta-llama/Llama-3.3-70B-Instruct | 70B | $0.052 input $0.156 output |
|
Llama‑3.1‑8B‑Instruct
|
meta-llama/Meta-Llama-3.1-8B-Instruct | 8B | $0.008 input $0.02 output |
|
Llama 3.2 Vision
|
meta-llama/Llama-3.2-11B-Vision-Instruct | 11B | $0.072 input $0.072 output |
|
Qwen‑2.5‑72B‑Instruct
|
Qwen/Qwen2.5-72B-Instruct | 72B | $0.065 input $1.25 output |
|
Qwen2.5-VL 72B
|
Qwen/Qwen2.5-VL-72B-Instruct | 72B | $0.40 input $0.40 output |
|
Qwen2.5-VL 32B
|
Qwen/Qwen2.5-VL-32B-Instruct | 32B | $0.325 input $0.325 output |
|
Qwen3 32B
|
Qwen/Qwen3-32B | 32B | $0.05 input $0.15 output |
|
Qwen3 A3B 30B
|
Qwen/Qwen3-30B-A3B-Instruct-2507 | 30B | $0.05 input $0.15 output |
|
Qwen 3‑14B
|
Qwen/Qwen3-14B | 14B | $0.04 input $0.12 output |
|
Qwen 3‑8B
|
Qwen/Qwen3-8B | 8B | $0.014 input $0.055 output |
|
QwQ‑32B
|
Qwen/QwQ-32B | 32B | $0.075 input $0.225 output |
|
Gemma‑3‑27B‑in‑chat
|
google/gemma-3-27b-it | 27B | $0.05 input $0.15 output |
|
Gemma‑3‑12B‑in‑chat
|
google/gemma-3-12b-it | 12B | $0.04 input $0.08 output |
|
Gemma‑3‑4B‑in‑chat
|
google/gemma-3-4b-it | 4B | $0.016 input $0.032 output |
|
Mistral Small 3.2 2506
|
mistralai/Mistral-Small-3.2-24B-Instruct-2506 | 24B | $0.04 input $0.08 output |
|
Mistral Nemo 2407
|
mistralai/Mistral-Nemo-Instruct-2407 | 12B | $0.02 input $0.06 output |
|
InternVL3‑78B
|
OpenGVLab/InternVL3-78B | 78B | $0.125 input $0.325 output |
|
InternVL3‑38B
|
OpenGVLab/InternVL3-38B | 38B | $0.125 input $0.325 output |
|
InternVL3‑14B
|
OpenGVLab/InternVL3-14B | 14B | $0.072 input $0.072 output |
|
InternVL3‑9B
|
OpenGVLab/InternVL3-9B | 9B | $0.05 input $0.05 output |
|
DeepSeek‑R1
Coming Soon
|
deepseek-ai/DeepSeek-R1 | 671B | $0.28 input $1.00 output |
|
DeepSeek‑V3
Coming Soon
|
deepseek-ai/DeepSeek-V3 | 671B | $0.112 input $0.456 output |
|
Llama‑4‑Maverick‑17B‑128E‑Instruct
Coming Soon
|
meta-llama/Llama-4-Maverick-17B-128E-Instruct | 400B | $0.075 input $0.425 output |
|
Llama‑4‑Scout‑17B‑Instruct
Coming Soon
|
meta-llama/Llama-4-Scout-17B-16E-Instruct | 109B | $0.05 input $0.25 output |
|
Qwen3 Coder A35B 480B
Coming Soon
|
Qwen/Qwen3-Coder-480B-A35B-Instruct | 480B | $0.32 input $1.25 output |
|
Qwen3 A22B 2507 235B
Coming Soon
|
Qwen/Qwen3-235B-A22B-Instruct-2507 | 235B | $0.075 input $0.40 output |
|
Kimi K2
Coming Soon
|
moonshotai/Kimi-K2-Instruct | 1T | $0.30 input $1.25 output |
|
GLM 4.5
Coming Soon
|
zai-org/GLM-4.5 | 358B | $0.30 input $1.10 output |
|
GLM 4.5 Air
Coming Soon
|
zai-org/GLM-4.5-Air | 110B | $0.16 input $0.88 output |
|
GLM 4.5V
Coming Soon
|
zai-org/GLM-4.5V | 108B | $0.30 input $0.90 output |
No models found matching your search criteria.
Request one above
Request one above
PROVIDED BY
Modular has partnered with San Francisco Compute to create Large Scale Inference, the best priced OpenAI-compatible inference in the world. On most open source models, we're 85%+ cheaper than other options. San Francisco Compute built LSI in close partnership with a tier-1 AI lab to help them print trillions of tokens of synthetic data, saving them tens of millions of dollars compared to the leading competitor.
Start building with Modular
Request a demo