

What if you could interact with your documents and get real-time, accurate answers, directly from them? In this post, we’ll dig into how we built a RAG app backed by MAX, our framework for GenAI, with Streamlit for the UI. Thanks to new features in MAX 24.5, you can have a bespoke chatbot running locally on your machine with state-of-the-art Llama3.1 performance, using only the Python programming language.
We built the Llama3.1 pipeline we’re featuring here with our MAX Graph API for Python: an API that empowers you to build high-performance AI models and related processing code using only Python. We’ll show how you can seamlessly integrate this pipeline into any Python app and benefit from the performance of MAX under the hood.
Just want the code?
The 📱example app and 🦙Llama3.1 pipeline are on GitHub!
About RAG
RAG stands for Retrieval-Augmented Generation. Training a large language model with new knowledge is not feasible for most people — it’s time-consuming and prohibitively expensive. RAG is a technique we can use to provide new knowledge to the model by retrieving specific, relevant information from external documents.
Key to this process is creating embeddings and storing them in a vector database. Embeddings are numerical representations of text that capture its meaning; we store these in a vector database to search through them. For this app, we’re using a Python library called fastembed to create our embeddings. We’re then storing them in ChromaDB, a powerful vector database that’s easy to set up right from our Python code.
About Streamlit
Every app needs a user interface, and Streamlit provides a simple yet powerful way to build web interfaces for Python scripts. We’re using it here because it provides out-of-the-box tools that enable users to interact with data — no HTML or JavaScript code required. If you’re new to it, we recommend you skim through the basics of Streamlit first.
Set up Hugging Face access
Llama’s knowledge — as with all LLMs — comes from parameter weights learned during the training process. Hugging Face is the most popular hub for such weights.
To interact with model weights hosted on Hugging Face, secure access is required either via SSH or an access token. Follow the instructions in the Hugging Face documentation to set up SSH. You can verify your configuration by running this in your terminal:
A successful setup will display: Hi <username>, welcome to Hugging Face.
Clone the project
Using a virtual environment ensures you have the MAX and Python versions compatible with this project. We'll use the Magic CLI to create the environment and install the required packages.
Don't have the Magic CLI yet? Run this command in your terminal and follow the instructions:
To clone the main branch of the MAX GitHub repository, run the following commands in your terminal:
If you encounter any problems cloning with git, please refer to GitHub's documentation.
Get acquainted
Let’s get a lay of the land before we dig into the app. Browsing through the project directory, you’ll see some important files and folders:
mojoproject.toml— This is the configuration file Magic uses to set up a Python environment, install dependencies, and run the app. This is a straight-Python project despite this file having Mojo in its name.home.py— This is the entrypoint of our app. It contains a menu where the user can select a model to interact with. For this tutorial, we’re only concerned with the Llama3.1 model.pages/llama3_1.py— This contains the bulk of our app, and is where most user interaction happens.shared.py— This contains helper utilities for working with RAG data, Hugging Face, and more. It also contains our app’s system prompt and chat message template — more on this later.pipelines/python/llama3— This directory contains the Llama3.1 model implemented with the MAX Graph API for Python.ragdata— This is where you place documents you want to chat with! Supported formats are:.txt, .pdf, .csv, .docx, .epub, .ipynb, .md, and .html
Run the example
Let’s run the app and examine the code side-by-side. Run the following in your terminal:
You should see output similar to the following:
Feel free to open the local URL and play around with Llama3.1! You’re running the leading open source LLM right on your machine. Take note of performance benchmarking in the sidebar as you chat. You can even try loading your own documents in the ragata folder.
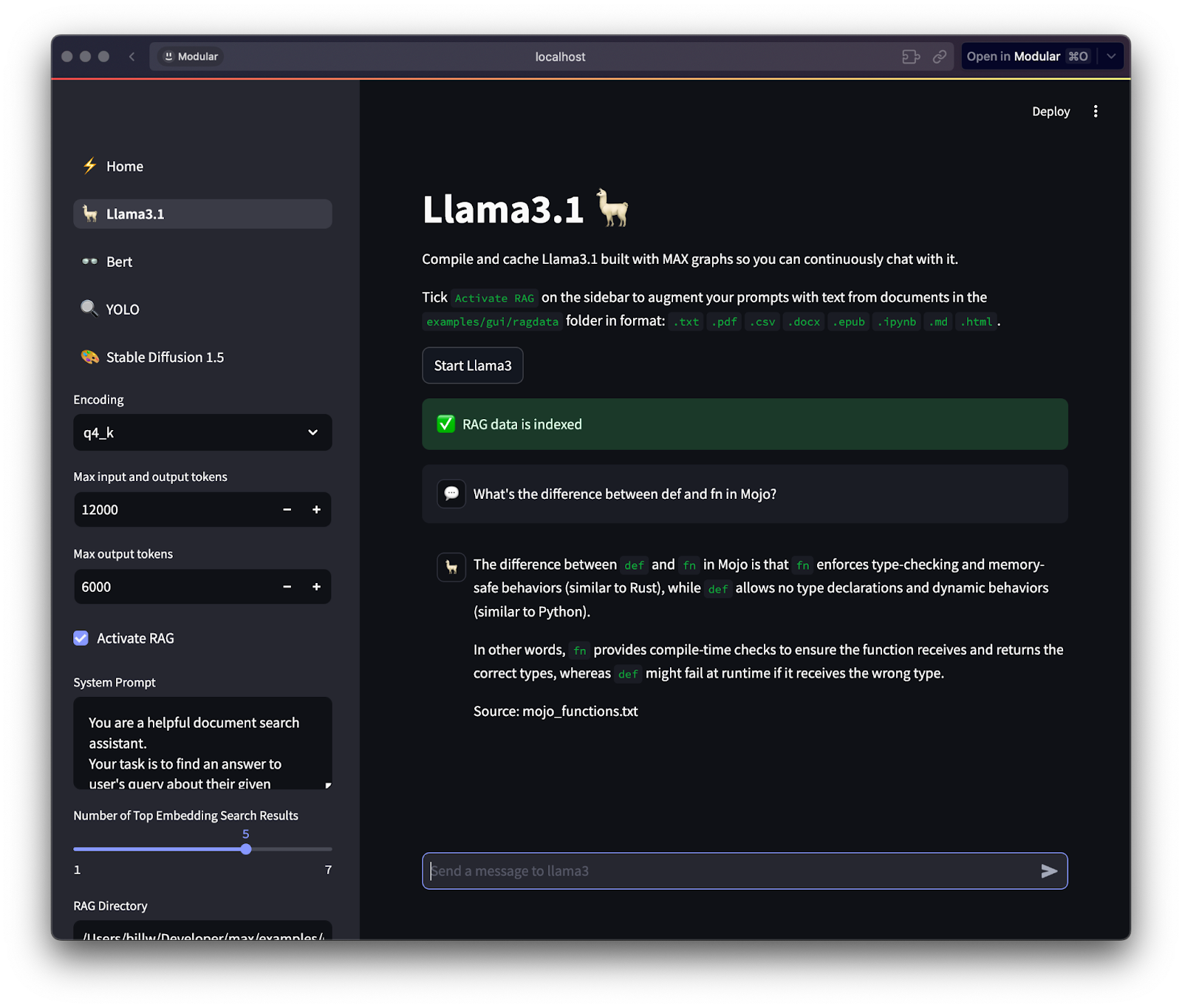
Under the Hood with Llama
From the home page of our app, click on the 🦙Llama3.1 button. You should see a chat window with a sidebar that contains some settings.
When you click on the Start Llama3 button, the Llama3.1 model will take some time to compile the first time you run it; subsequent startups will be faster. Next, open up pages/llama3_1.py so we can look at the source code that's running. Toward the top of that file, we declare the function start_llama3:
Note: The line numbers on this blog refer to those in the code blocks on this page, not the line numbers of the actual Python files.
Above at lines 3-4, the start_llama3 function is marked with Streamlit’s @st.cache_resource decorator. When we use this decorator on our function, Streamlit caches the instance of the compiled MAX model. MAX plays nicely with libraries like Streamlit in this way — it’s one of its key advantages.
In the code block below, you can see how we provide an option in our Streamlit app’s sidebar for selecting a quantization. LLMs work by turning words into numbers (vectors) that the model can understand. Quantization is a way to simplify those numbers to use less memory and run faster, without losing much accuracy.
The SupportedEncodings constants (used at lines 6-8 above) are part of our Llama3.1 pipeline for MAX. We’ll use the selection later when downloading weights from Hugging Face.
Next, we have options for the number of tokens to handle. Tokens are small chunks of text — like words or parts of words — that an LLM reads and processes to understand and generate sentences.
Let’s break down the code above:
- Lines 3-9 map the encoding the user selects to the name of the model weights to download from Hugging Face.
“Max input and output tokens”(lines 11-13) is for selecting the total number of tokens in both the input and output combined. This ensures the model doesn’t exceed memory or compute limits.“Max output tokens”(line 15) is for selecting how many tokens the model can generate for each response. This prevents excessively long responses and manages performance.- Line 17 downloads the model weights from Hugging Face using a function in our
shared.pyfile.
Finally, in the code block below, you'll see we have some code to start the model, passing in the parameters for weights, encoding, and our token selections:
This result of the call to start_llama at line 7 is stored in Streamlit's st.session_state object for persistence. Note the button_state and model_state variables at lines 3-4: we use these to tell Streamlit to persist the state of the button and some additional information regarding our model.
Activate RAG
In the sidebar of the app, you should see a checkbox for Activate RAG; click it now. After a second or two, you should see a message: “RAG data is indexed.” Open up shared.py so we can dig into what happened.
Below, you'll see how we place the Activate RAG checkbox in the sidebar (line 3), along with the system prompt (line 6), additional input fields (lines 10-12 and 13-16), and business logic for handling our RAG documents (lines 17-25):
Next, in the code block below we see the RAG system prompt itself, which is found in another file, shared.py. A system prompt is a set of instructions given to a language model at the start of a conversation to guide how it should behave and respond.
As you learned earlier, RAG works by creating vector embeddings of our documents. When you clicked on Activate RAG, the load_embed_docs function found in shared.py was called:
Here’s what happening inside load_embed_docs:
- We first read the files stored in the
ragdatadirectory (line 6 above). - Once the files have been loaded, we need a place to store them. This is where ChromaDB and fastembed come into play.
- We create a ChromaDB instance and access a
max-rag-examplecollection within it (lines 7-10). - Then we create an embedding model with fastembed (line 11).
- All of this in hand, we can create embeddings for our documents, and store each document’s text and embeddings in the ChromaDB collection (lines 13-20).
- Finally, we return the collection and embedding model so we can use them with our Llama3.1 MAX pipeline (line 22).
Note: the files_observered argument in load_embed_docs is intentionally unused, but is necessary to "hot reload" new and modified files within the rag_directory; we must pass the variable to the function like this because of how the @st.cache_resource decorator works internally.
Prepare chat messages
When you clone this repo, the ragdata folder has a single file, mojo_functions.txt. This file contains an explanation of the difference between def and fn in the Mojo programming language. Therefore, to test our app we can try asking it:
What’s the difference between fn and def in Mojo?
The response is pretty neat, isn't it? Let’s examine how it works:
This first block of code above relates to chat history:
- Within
pages/llama3_1.py, you will find multiple references tost.session_state.messages, which is how we store chat history with Streamlit. - At lines 8-10 above, you can see that we display messages from previous interactions by iterating through the chat history stored in
session_state.message.
- Finally, at line 12 you can see that we have
disable_chat, which is a boolean we set to disable the ability to chat when the model is not ready.
In the code block below, we see the bulk of the code for chatting with the model. (This code uses one of Python’s most fun and useful features, the walrus operator :=) Here, we run Streamlit’s st.chat_input when the user sends a new message:
Let’s breakdown the code above:
- We begin preparing content to send to the model by creating a list of dictionaries (lines 4-8 above), a common pattern when working with LLMs in Python:
- The
rolefield can beuserorsystem, and the content is the message itself - The first message is our system prompt (line 4)
- Next, we add previous message history to the list of messages to send (lines 5-8)
- The
- Since we have activated RAG (line 9), we will use the embedding model and ChromaDB collection that were returned when we called
load_embed_docs:- We use the embedding model to create an embedding for the user’s query (line 10)
- Next, we query the ChromaDB collection for relevant documents (line 11)
- We then join the document content together (lines 12-17)
- Finally, we append the documents to the message history (lines 18-23)
To instruct Llama3.1 how it should use these documents, we need to “stuff” the documents into the RAG_PROMPT string. We do this with line 21 in the code block above: RAG_PROMPT.format(query=prompt, data=data)
For reference, here's the contents of that template, which you can find in shared.py:
Above at line 3, you can see how {query} and {data} are injected alongside instructions we provide to the Llama3.1 model.
Stream model response
Finally, we’re ready to send our messages to the model and stream its output:
In the code above:
- First, we display the user’s message in the chat window, preserving how the user typed it in (lines 7-8).
- Next, we prepare the messages for the model by converting the chat history into a specially formatted prompt string using
messages_to_llama3_prompt(line 10).- This function (which is defined within
shared.py) combines all messages with specific tokens like<|begin_of_text|>and<|start_header_id|>that help the model understand the structure of the conversation.
- This function (which is defined within
The formatted prompt is then passed to stream_output (lines 15-18), which uses Python's asyncio library to handle the asynchronous token generation. Under the hood, this function creates a new context for the model and yields tokens one at a time, updating a Streamlit element in real-time to create a smooth streaming effect. Finally, you can see we persist the user's new message and Llama3.1's response using Streamlit's st.session_state object at lines 20-23 above.
Wrapping up
In this post, you’ve learned how to harness Streamlit to build a user-friendly interface for interacting with our MAX Pipeline for Llama 3.1 on your local machine. This app integrated the MAX Engine to handle inference requests and employed ChromaDB with fastembed for Retrieval-Augmented Generation (RAG). You saw how with a user’s text input, the app searches through embeddings stored in a vector database, retrieves relevant information, and returns a contextually informed response generated by the model.
We encourage you to use what you learned here to deploy other models, and extend this example as needed to explore MAX even more.

