

The landscape of Generative AI is rapidly evolving, and with it comes the need for more efficient, flexible ways to deploy and interact with Large Language Models (LLMs). With the release of Meta's Llama 3 and MAX 24.6, developers now have access to a truly native Generative AI platform that simplifies the entire journey from development to production deployment.
MAX 24.6 introduces MAX GPU, our new vertically integrated serving stack that delivers high-performance inference without vendor-specific dependencies. At its core are two revolutionary technologies:
- MAX Engine, our high-performance AI model compiler and runtime, and
- MAX Serve, a sophisticated Python-native serving layer engineered specifically for LLM applications.
In this blog, we'll leverage these innovations to create a chat application that uses Llama 3.
In this blog, we will cover:
- How to set up a chat application using Llama 3 and MAX.
- Implementing efficient token management through rolling context windows.
- Handling concurrent requests for optimal performance.
- Containerizing and deploying your application with Docker Compose.
We'll walk through building a solution that showcases MAX's NVIDIA GPU-optimized capabilities, featuring efficient token management through rolling context windows, concurrent request handling, and straightforward deployment using Docker Compose for demonstration. For more details on deployment, check out our tutorials on deploying Llama 3 on GPU with MAX Serve to AWS, GCP or Azure or on Kubernetes. Our implementation demonstrates how MAX Serve's native Hugging Face integration and OpenAI-compatible API makes it simple to develop and deploy high-performance chat applications.
Whether you're building a proof-of-concept or scaling to production, this guide provides everything you need to get started with Llama 3 on MAX. Let's dive into creating your own GPU-accelerated chat application using our native serving stack, designed to deliver consistent and reliable performance even under heavy workloads.
Quick start: running the chat app
Getting started with our chat app is straightforward. Follow these steps to set up and run the application. All code is available in our GitHub repository.
Prerequisites
Ensure your system meets these requirements:
- Supported GPUs: NVIDIA A100 (optimized), A10G, L4, or L40.
- Docker and Docker Compose: Installed with NVIDIA GPU support.
- NVIDIA Drivers: Installation guide here.
- NVIDIA Container Toolkit: Installation guide here.
- Hugging Face Account: Obtain your access token and make it available as environment variable.
- Access to Llama 3 Model: Confirm access to meta-llama/Meta-Llama-3-8B on Hugging Face.
Clone the repository
Clone the Llama 3 Chat repository to your local machine:
Build the docker images
Create and use a Docker builder (required only once):
Build the UI image for your platform:
Start the services
- If you don't have access to the supported NVIDIA GPU locally, you can instead follow our tutorials on deploying Llama 3 on GPU with MAX Serve to AWS, GCP or Azure or on Kubernetes to get a public IP (running on port 80) and then run the UI component separately as follows:
- Or if you do have local access to the supported NVIDIA GPU locally, launch the services via Docker Compose:
Once the Llama3 server and UI server are running, open http://localhost:7860 to view the chat interface:
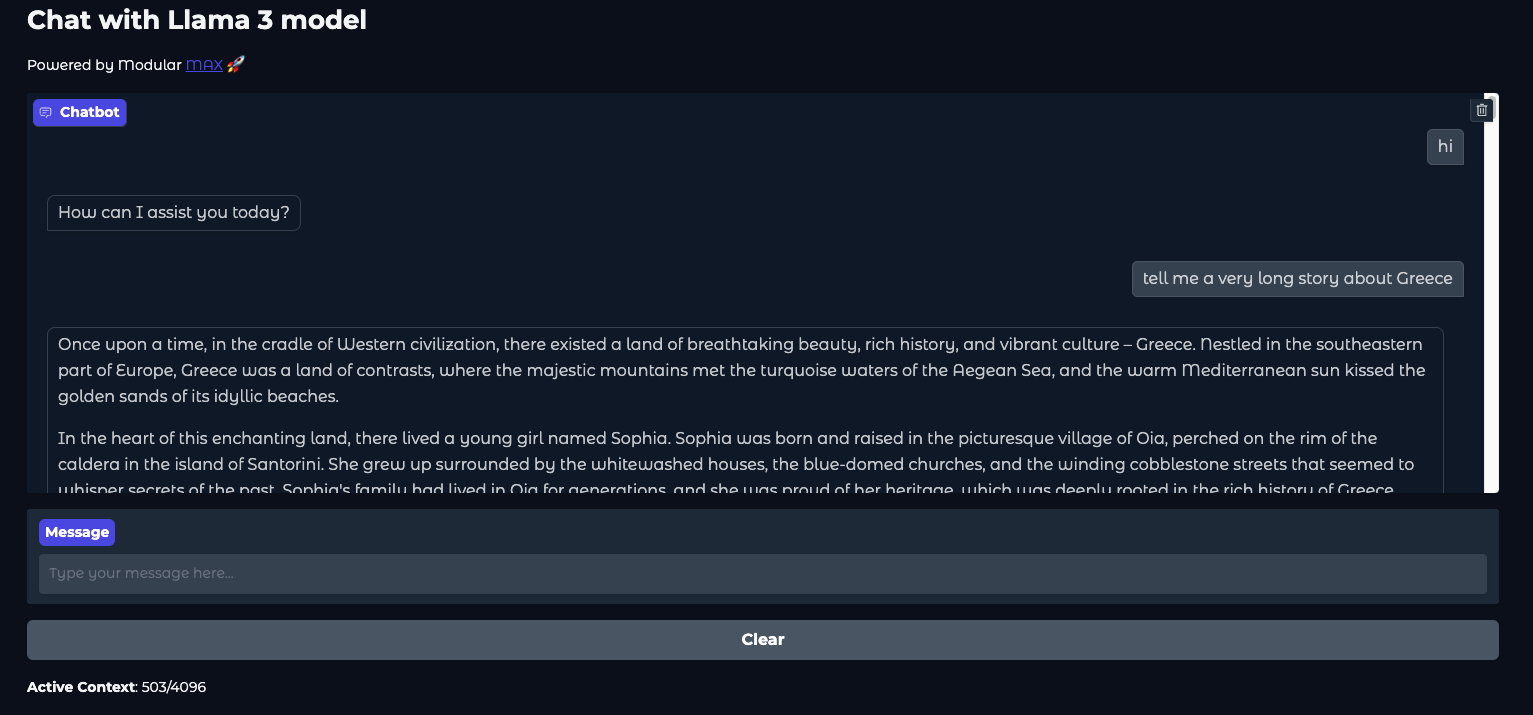
Development
Alternatively, in particular for development, we can run the MAX Serve docker individually on a compatible GPU machine:
and launch the UI separately via the magic CLI (install Magic if you haven’t already and for more check out this step-by-step guide to Magic):
Note: Check the available UI options magic run python ui.py --help. For example, this also enables launching the UI that connects to a remote public IP as follows:
Features of Llama 3 chat app
- Gradio-based interface: A sleek, interactive UI built with Gradio for intuitive interactions.
- Seamless integration: Leverages Llama 3 models via MAX Serve on GPU, ensuring rapid and efficient chat responses.
- Customizable environment: Adjust settings like context window size, batch size, and system prompts to suit your needs.
- Efficient continuous chat: Employs a rolling context window implementation that dynamically maintains the chat context without exceeding the maximum token limit.
Architecture overview
Our chat application consists of three main components:
- Frontend layer: A Gradio-based web interface that provides real-time chat interactions.
- MAX Serve layer: Our OpenAI-compatible API server that handles:
- Request batching and scheduling through advanced techniques such as continuous batching.
- Token management and context windows.
- Model inference optimization.
- Model Layer: Llama 3 running on MAX Engine, optimized for GPU inference.
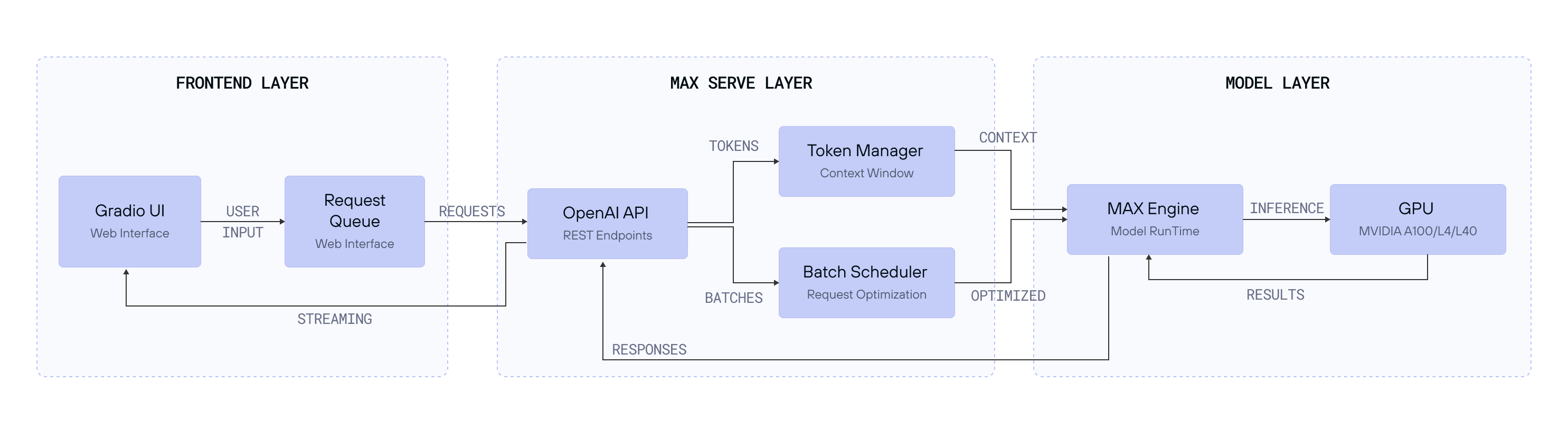
This architecture ensures:
- Efficient resource utilization through batched inference.
- Scalable request handling via concurrent processing.
- Optimized memory management with rolling context windows.
Technical deep dive
Continuous chat with rolling context window
A key feature of our chat application is the rolling context window. This mechanism ensures that conversations remain coherent and contextually relevant without overwhelming system resources. Here's an in-depth look at how this is achieved:
1. Dynamic token management
The ChatConfig class is responsible for tracking token usage and maintaining a rolling window of messages within the configured token limit. Tokens are the fundamental units processed by language models, and managing them efficiently is crucial for performance and cost-effectiveness.
How it works:
- Token counting: Each message's content is wrapped with special tokens (
<|im_start|>and<|im_end|>) to denote the start and end of a message. The tokenizer then encodes this text and counts the number of tokens. - Configuration: The
max_context_windowparameter defines the maximum number of tokens allowed in the conversation context. This ensures that the application doesn't exceed the model's capacity, maintaining efficiency.
2. Prioritized message inclusion
To maintain the conversation's relevance, the latest user and system messages are always included. Older messages are trimmed dynamically when the token count exceeds the window size.
How it works:
- Reversed iteration: By iterating over the chat history in reverse, the system prioritizes the most recent messages.
- Token check: For each pair of user and assistant messages, the total tokens are calculated. If adding these messages keeps the total within the
max_context_window, they are included in the active context. - Dynamic trimming: Once the token limit is approached, older messages are excluded, ensuring the context remains within bounds.
3. Efficient resource usage
By keeping the active context concise and relevant, the system optimizes resource usage and maintains high performance even during extended interactions. This approach prevents unnecessary memory consumption and ensures the application remains responsive.
Chat user-interface
The UI logic is included in ui.py file and is central to the continuous chat interface. Here’s how it enables the chat system:
Gradio Integration
Gradio provides a user-friendly interface, making interactions intuitive and accessible.
Key components:
- Markdown: Displays the application title and branding.
- Chatbot component: Shows the conversation history.
- Textbox: Allows users to input messages.
- Clear button: Resets the conversation.
- Token display: Shows the total tokens generated and the current context window usage.
- Asynchronous response handling: Ensures smooth and non-blocking interactions.
Server interaction
The interface communicates with the Llama 3 model via the MAX Serve API to fetch chat completions.
Health checks
The wait_for_healthy function ensures the MAX Serve API is ready before processing requests, retrying until the server is live.
Explaining docker-compose.yml
The docker-compose.yml content is as follows
The docker-compose.yml orchestrates both the UI and server components:
- UI Service:
- Builds the Gradio interface using
Dockerfile.ui. - Communicates with the server via the environment variable
BASE_URL.
- Builds the Gradio interface using
- Server Service:
- Runs the MAX Serve API using the specified image.
- Uses NVIDIA GPUs for inference, ensuring optimal performance.
- Shares necessary Hugging Face cache data via mounted volumes.
Dockerfile.ui component
We use the official magic-docker base image ghcr.io/modular/magic:noble to create our Dockerfile.ui as follows. It supports multi-platform builds by leveraging the following configuration:
To define target platforms for a multi-platform build, we include the following in docker-bake.hcl:
Configuration and customization
Environment variables
MAX_CONTEXT_WINDOW: Max tokens for the context window (default: 4096).CONCURRENCY_LIMIT: Must match theMAX_CACHE_BATCH_SIZEthat enables continuous batching in MAX Serve for efficient handling of concurrent streaming requestsSYSTEM_PROMPT: Default system prompt for the AI assistant.
Dependency management
All dependencies are managed via Magic and defined in pyproject.toml to ensure consistency across environments:
Performance considerations
When deploying your chat application, consider these key factors:
- Context window size
- Default: 4096 tokens (in MAX Serve
--max-length). - Larger windows increase memory usage but maintain more conversation context
- Recommended: Start with 4096 and adjust based on your use case.
- Continuous batching
MAX_CACHE_BATCH_SIZEcontrols concurrent request handling via the continuous batching (in MAX Serve--max-cache-batch-size).- Higher values increase throughput but may impact latency.
- Recommended: Start with 1 and increase based on your GPU capacity. MAX Serve also gives a recommendation at the start for the optimal size.
- Memory management
- Monitor GPU memory usage with
nvidia-smi. - Consider implementing additional caching for frequent responses.
Check out various configuration options by:
On the serving side, make sure to check out the benchmarking blog too.
Clean up (Optional)
To stop and clean up all resources:
Remove all images related to the project:
Remove the Docker builder (if no longer needed):
Conclusion
In this tutorial, we've built a functional chat application using Llama 3 and MAX 24.6. We've explored:
- Basic setup: Using Docker and NVIDIA GPU support to create a working environment
- Architecture overview: Creating a three-layer system with a Gradio frontend, MAX Serve API, and Llama 3 model backend
- Token management: Implementing rolling context windows to maintain conversation history
- Performance basics: Understanding batch processing and concurrent request handling
- Simple deployment: Using Docker Compose to run the application
- Configuration options: Managing environment variables and dependencies
This demo shows how MAX's GPU-optimized serving stack can be combined with Llama 3 to create interactive chat applications. While this implementation focuses on the basics, it provides a foundation that you can build upon for your own projects.
Next Steps
Deploy Llama 3 on GPU with MAX Serve to AWS, GCP or Azure or on Kubernetes.
Explore MAX's documentation for additional features.
Join our Modular Forum and Discord community to share your experiences and get support.
We're excited to see what you'll build with Llama 3 and MAX! Share your projects and experiences with us using #ModularAI on social media.


