.png)

Three years ago we set out to redefine how AI is developed and deployed. Our goal wasn’t simply to improve existing systems, but to rebuild AI infrastructure from the ground up to deliver a more performant, programmable, and portable infrastructure platform. We recognized that to address today’s challenges and stay ahead of rapid technological evolution, we needed to completely rethink the AI stack from first principles.
The arrival of large-scale Generative AI transformed the very nature of AI infrastructure. To meet its rapidly growing resource demands, GenAI requires innovations from the lowest levels of GPU programming all the way up to the serving layers, something that only Modular is positioned to do.
Today, we’re announcing the first step in this journey to meet these challenges with MAX 24.6, featuring a preview of MAX GPU. This GPU release showcases the power of the MAX platform, and is just the beginning of the advancements we’ll bring to AI infrastructure as we head into 2025. We’d love for you to follow along, and develop with us as we continue to advance AI infrastructure for the world in the coming months.
Introducing MAX GPU: A new GenAI native serving stack
At the heart of the MAX 24.6 release is MAX GPU– the first vertically integrated Generative AI serving stack that eliminates the dependency on vendor-specific computation libraries like NVIDIA’s CUDA.
MAX GPU is built on two groundbreaking technologies. The first is MAX Engine, a high-performance AI model compiler and runtime built with innovative Mojo GPU kernels for NVIDIA GPUs–free from CUDA kernel dependencies. The second is MAX Serve, a sophisticated Python-native serving layer specifically engineered for LLM applications. MAX Serve expertly handles complex request batching and scheduling, delivering consistent and reliable performance, even under heavy workloads.
Unlike existing tools that address only specific parts of the AI workflow, MAX is designed to support the entire development experience–from initial experimentation, through deployment, and to production. MAX offers a unified platform for exploring new models, testing and optimization, and delivery of high-performance inference capabilities that before now required piecing together legacy technology.
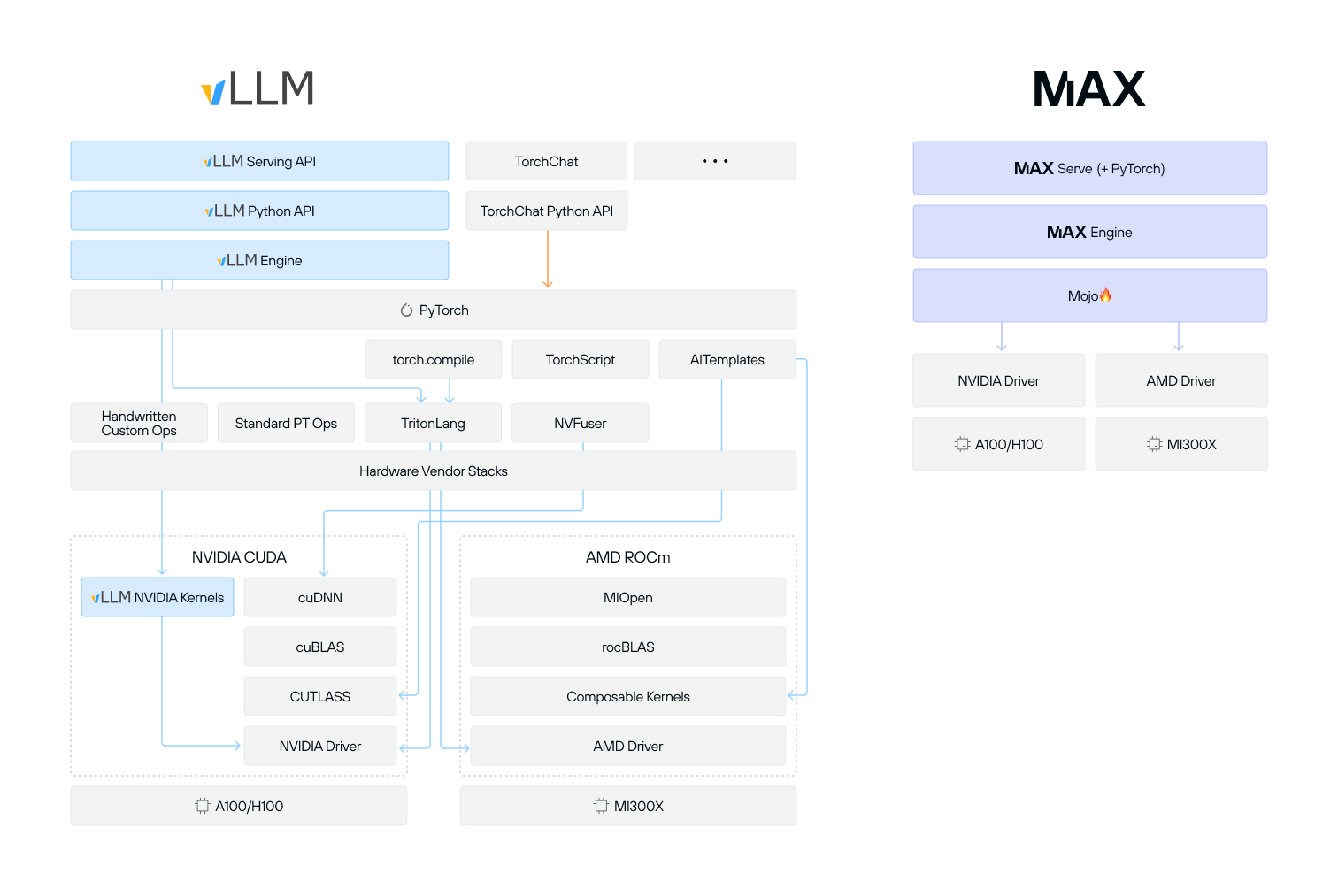
We cannot overstate how important this diagram is to our mission and vision of simplifying and making AI infrastructure accessible to everyone. We have strived to vastly reduce complexity across the AI infrastructure stack, and as you can see above, MAX reduces the incredible fragmentation of today's ecosystem. As a developer, it has become enormously challenging to navigate this landscape with such a vast array of differing technologies. We have been building for a new approach, and want to ensure the whole world can build with us.
We can now ship an uncompressed Docker container, without CUDA toolkit for NVIDIA GPUs, that drops our total size to under 3.7 GB vs. vLLM container which is 10.6GB - a 65% reduction. For customers that don't need PyTorch, and want to use MAX Graphs only, it drops even further to just 2.83GB. When we compress this, it's under 1GB in size.
Enterprise-grade development to deployment flexibility
MAX Engine enables flexible inference deployments across multiple hardware platforms, allowing developers to experiment locally on laptops and scale seamlessly into production cloud environments. Combined with MAX Serve’s native Hugging Face model support, teams can rapidly develop, test, and deploy any PyTorch LLM. Custom weight support, including Llama Guard integration, further enables developers to tailor models for specific tasks.
When it’s time to put a model into production, MAX Serve provides an OpenAI-compatible client API, shipped in a compact Docker container that works on NVIDIA platforms. Teams can then deploy models across all major clouds, including AWS, GCP, and Azure, with options for both direct VM deployment and enterprise-scale Kubernetes orchestration. This flexibility ensures that you can host your own models securely, keeping your GenAI infrastructure fully under your control.
At the heart of this workflow is Magic, Modular’s command-line tool that streamlines the entire MAX lifecycle. Magic handles everything from installation and environment management, to development and deployment–making it easier to manage your AI infrastructure. Read more about Magic here.
High-performance GenAI models and hardware portability
We’re also expanding MAX’s power with new high-performance models. These models deliver optimized implementations of many popular LLMs like Llama and Mistral. When running out-of-the-box on NVIDIA GPUs, MAX matches the performance of the established AI serving framework vLLM in standard throughput benchmarks. These models also support a range of quantization approaches, and we are working incredibly hard for this collection of native MAX models to define SOTA performance in the coming weeks and months.
The industry-standard ShareGPTv3 benchmark demonstrates MAX GPU’s performance capabilities with Llama 3.1, achieving a throughput of 3860 output tokens per second on NVIDIA A100 GPUs using only MAX’s innovative NVIDIA kernels–with GPU utilization greater than 95%. We’re currently achieving this level of performance without optimizations like PagedAttention - which will land early next year. All this is to highlight we’re just getting started, our numbers will only continue to improve and we make it easy to run these benchmarks yourself.
MAX GPU launches with support for NVIDIA A100, L40, L4, and A10 accelerators, the industry standards for LLM inference and the most optimized GPUs on the market–with H100, H200, and AMD support landing early next year.

Built to enable hardware portability
Up next is bringing up support for AMD MI300X GPUs which we are currently refining, and expect to deliver it soon. MAX's NVIDIA and AMD kernels are built on the same underlying technology, making it possible for us to rapidly support new hardware platforms. We’ll share the exciting details about our AMD bring-up shortly, and will continue to expand our AMD support through early 2025.
Try MAX 24.6 today & our nightly releases
We’re excited to invite developers to explore this early technology preview of MAX GPU and see how it can transform your AI workflow. Despite being a preview, this release is still packed with lots of features and capabilities like the new high-performance models running on NVIDIA GPUs, compatibility with OpenAI APIs, and interoperability with Hugging Face models.
Get started running Llama 3 on MAX GPU now!
This is just the beginning–in 2025, we’ll continue to expand our GPU technology stack, delivering even greater performance across more Generative AI modalities, such as text-to-vision and multi-GPU support for larger models. We’re also focusing on enhancing portability to new hardware architectures, along with introducing a complete GPU programming framework for low-level control and customization.
To help you stay ahead of these advancements, we’ve released detailed documentation for our nightly builds, making it easier to install and leverage the latest GPU features straight from the development branch.
As we wrap up the year, we want to extend our warmest wishes to all of you. 2025 is shaping up to be a pivotal year for AI infrastructure, and we’re thrilled to be at the forefront of this transformation. We could not be more excited. We look forward to continuing this journey with you in the new year—see you in January!