.png)
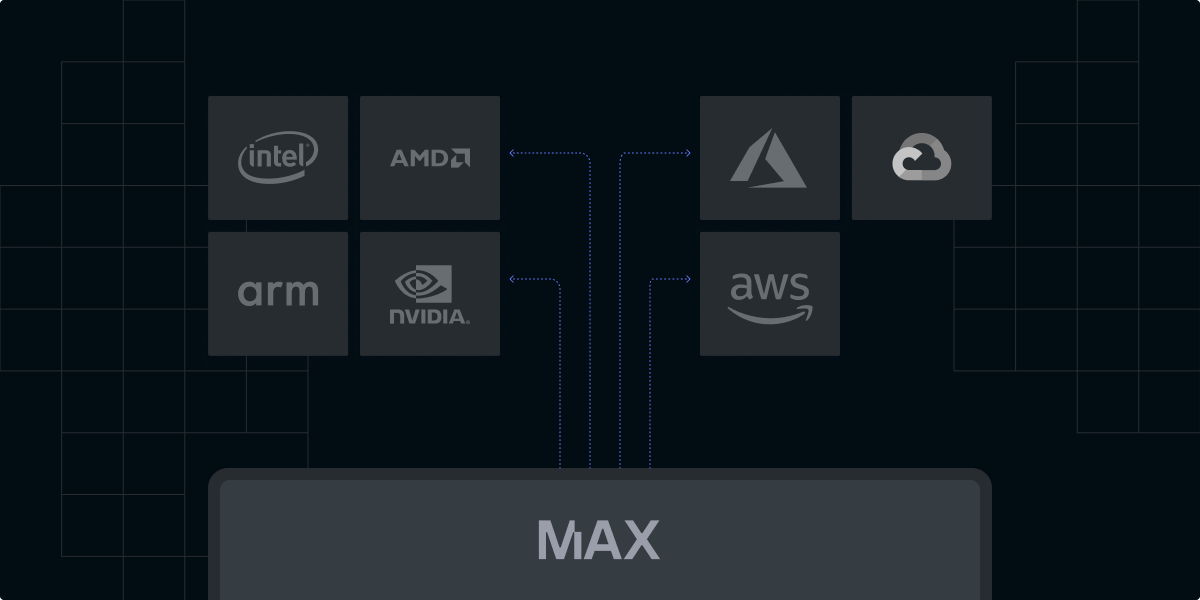
The recent surge in AI application development can be attributed to several factors: (1) advancements in machine learning algorithms that unlock previously intractable use cases, (2) the exponential growth in computational power enabling the training of ever-more complex models, and (3) the ubiquitous availability of vast datasets required to fuel these algorithms. However, as AI projects become increasingly pervasive, effective development paradigms, like those commonly found in traditional software development, remain elusive.
In particular, it remains nearly impossible to build streamlined and scalable development workflows that bridge the gap between local development and cloud deployment. These workflows are complicated because AI tooling is fragmented, with each tool presenting its own trade-offs and limitations.
Today’s AI developers must leverage a multitude of different tools across their end-to-end AI workflows. Some tools work for cloud accelerators but are limited to local CPUs, while others excel for local CPU development but aren’t cloud-enabled. Working across these tools requires problematic abstractions and translators to unify fundamentally incompatible technologies, requiring rewriting of model or application code to make it all work together.

Sometimes, it seems impossible to piece together the right combination of tools and hardware to support the full developer lifecycle and provide the best performance-to-cost trade-off for any given model.
How MAX helps
MAX solves these problems by providing a unified inference API backed by a state-of-the-art compiler and inference runtime that works with a variety of models and hardware types across local laptops and common cloud instances. MAX doesn't require you to migrate your entire AI pipeline and serving infrastructure to something new—it meets you where you are now and allows you to upgrade incrementally.
MAX makes your pipeline portable across a wide range of CPU architectures—Intel, AMD, and ARM—and GPUs, opening up more portability and performance. MAX allows you to take advantage of the breadth and depth of different cloud instances at the best price, ensuring you always get the best inference cost-performance ratio.
MAX unlocks local to cloud
With MAX, you can develop AI applications locally and then easily package them for deployment to any cloud environment. This unified workflow offers several critical advantages:
- Speed and Flexibility: Downloading MAX enables local development for rapid iteration and testing. Importantly, MAX doesn’t just run locally but is faster on many use cases than industry standard local LLM frameworks, like llama.cpp, making development even faster. You can quickly modify code, run experiments, and debug issues without the setup and latency associated with remote servers.
- Resource Availability: On local machines, you have direct access to local hardware resources, such as CPU and GPUs, for free. Spinning up and paying for cloud instances is unnecessary and isn’t bottlenecked by availability.
- Control and Customization: Local environments can be tailored to specific project needs, allowing developers to install custom libraries, frameworks, and tools without restrictions. Importantly, for latency-sensitive applications, fully controlled local development boxes provide less noise than shared cloud instances.
- Consistency: Developing with MAX locally and bundling our infrastructure into OCI-compatible containers like Docker means you can ensure that what you build locally works seamlessly in production environments.
- Global Scale: Finally, MAX is highly optimized for the AI hardware running in popular data center cloud providers like AWS, Azure, and GCP—including CPU and GPUs (coming soon!). Users can scale their AI applications globally with no code changes and state-of-the-art performance.
How MAX works
The industry lacks a unified AI infrastructure platform and is instead flush with “point solutions” that only work for specific models, hardware, and OS’s. When we began the effort to unify the world's AI infrastructure, we realized fragmentation in the stack was driven by a lack of a common programming model for AI hardware. That's why we created Mojo, a new unifying programming language for AI hardware that combines Python’s expressiveness with C’s performance.
Mojo is the core technology that provides the foundation for the rest of the MAX platform. The MAX Engine, our next-generation graph compiler and runtime system, leverages Mojo to implement its low-level mathematical operations, such as MatMul. This provides unparalleled portability and performance and makes local-to-cloud workflows possible. You can load any model into MAX Engine and achieve low-latency inference on a wide range of hardware.

All that said, you do not need to use Mojo to use MAX. You can bring your existing models to the framework and execute them with MAX Engine using our API libraries in Python and C. However, using Mojo with MAX gives you superpowers. Mojo allows you to write custom ops for your model or write a full inference graph for optimal performance in MAX Engine.
Finally, integrating MAX as part of your AI development workflow makes it easy to deploy your locally developed models into production using trustworthy tools that include robust scaling, monitoring, and deployment templates.
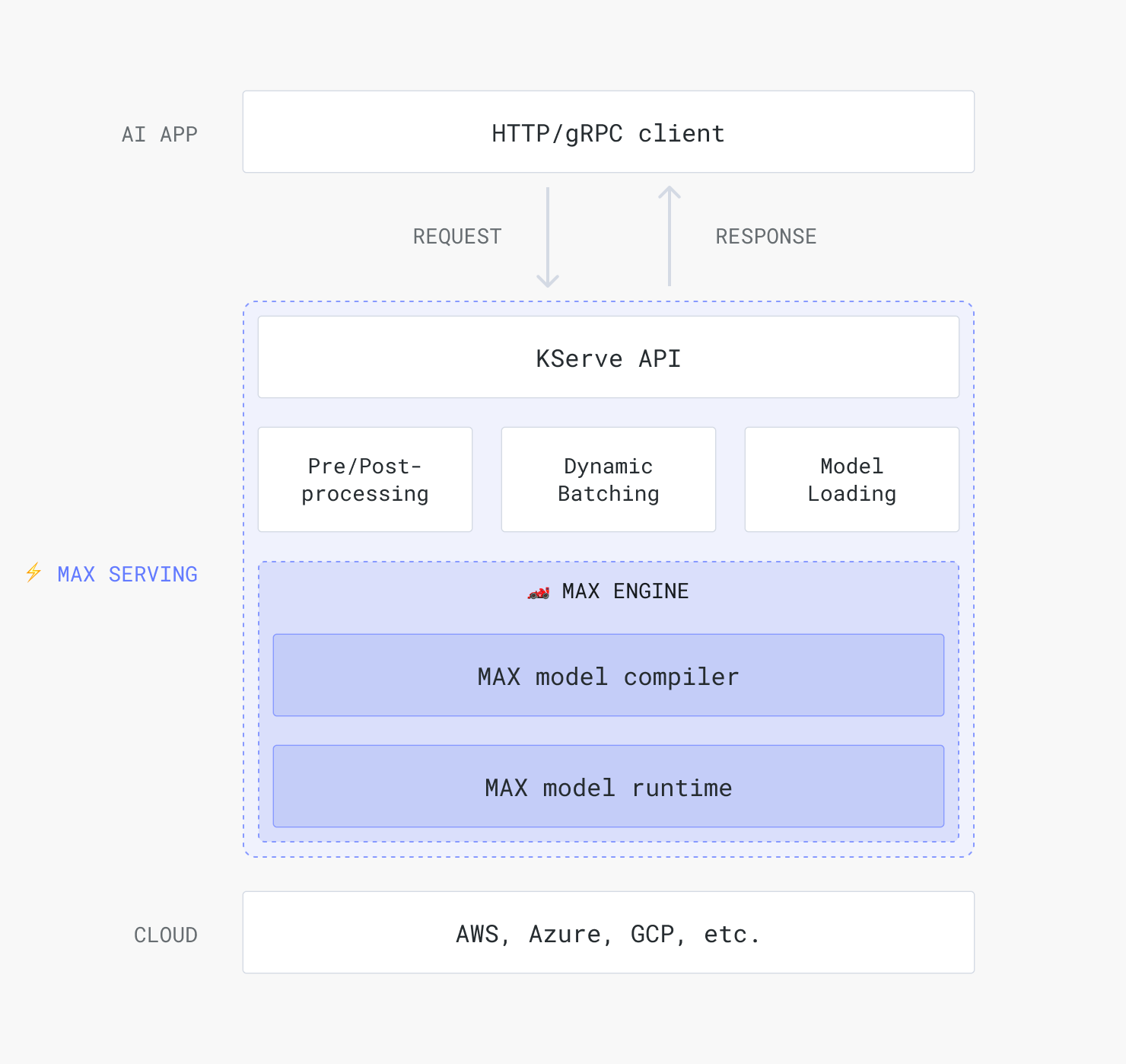
With MAX, you can serve your model using industry-compatible tools, including NVIDIA's Triton Server. Because we already interoperate with the tools you already use, we make it easy to drop MAX into your existing workflows that require model versioning, multi-model deployment, and support for various deployment environments, making it a versatile solution for AI inference deployment. Read about how easy this is right now!