

In our recent MAX 24.4 release, we announced the availability of MAX on MacOS and MAX Pipelines with native support for local Generative AI models such as Llama3. Together, these innovations establish a new industry standard paradigm, enabling developers to leverage a single toolchain to build Generative AI pipelines locally and seamlessly deploy them to the cloud, all with industry-leading performance.
In this blog post, we will explore various features of MAX Pipelines and their benefits for GenAI applications such as native GGUF, tokenizer and quantization support. To follow along, please ensure you have installed MAX 24.4. Note that MAX now ships with Mojo for all platforms. If you previously installed a standalone version of Mojo, you should uninstall it and install MAX instead. After installing MAX, you should get the following hash release when running max -v
Get Started with MAX Pipelines
Let’s start with running quantized Llama3 pipeline in pure Mojo locally as follows
On my M3 MacBook Pro, it outputs
Fantastic 🎉 now we are ready to explore more features.
Native GGUF Support in Mojo
GGUF has become a standard file format for storing models for inference workload and specially is suitable for single-file deployment of LLMs. MAX Pipelines natively supports gguf in Mojo. GGUF specification is as follows

Our native implementation parses GGUF file format in preparation for inference ensuring optimal performance and integration within MAX Pipelines. This feature is fully integrated, allowing developers to efficiently load and utilize GGUF models without additional configuration.
Native Tokenizer Support in Mojo
MAX Pipelines provides native Mojo support for tokenizer, enabling efficient text preprocessing directly within your Mojo applications. This integration offers several benefits, ensuring that your Generative AI models can handle natural language input with high performance and accuracy.
Quantization Support
Quantization is a well-known technique to reduce memory and computational costs of running deep learning models. MAX Pipeline supports llama.cpp quantization encoding such as
- Q4_0: 4-bit block quantization where weights are divided in blocks of 32 weights. The scale of each block is stored as float16 format.
- Q4_K: 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. The scale and minimum of each super-block are stored as float16. The scales and minimums of each block in a super-block are quantized with 6-bits. On average, this ends up using 4.5 bits-per-weight.
- Q6_K: 6-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. The scale of each super-block is stored as float16. The scale of each block is quantized with 8 bits. On average, this ends up using 6.5625 bits-per-weight.
Here is a visual demonstration of these quantization schemes
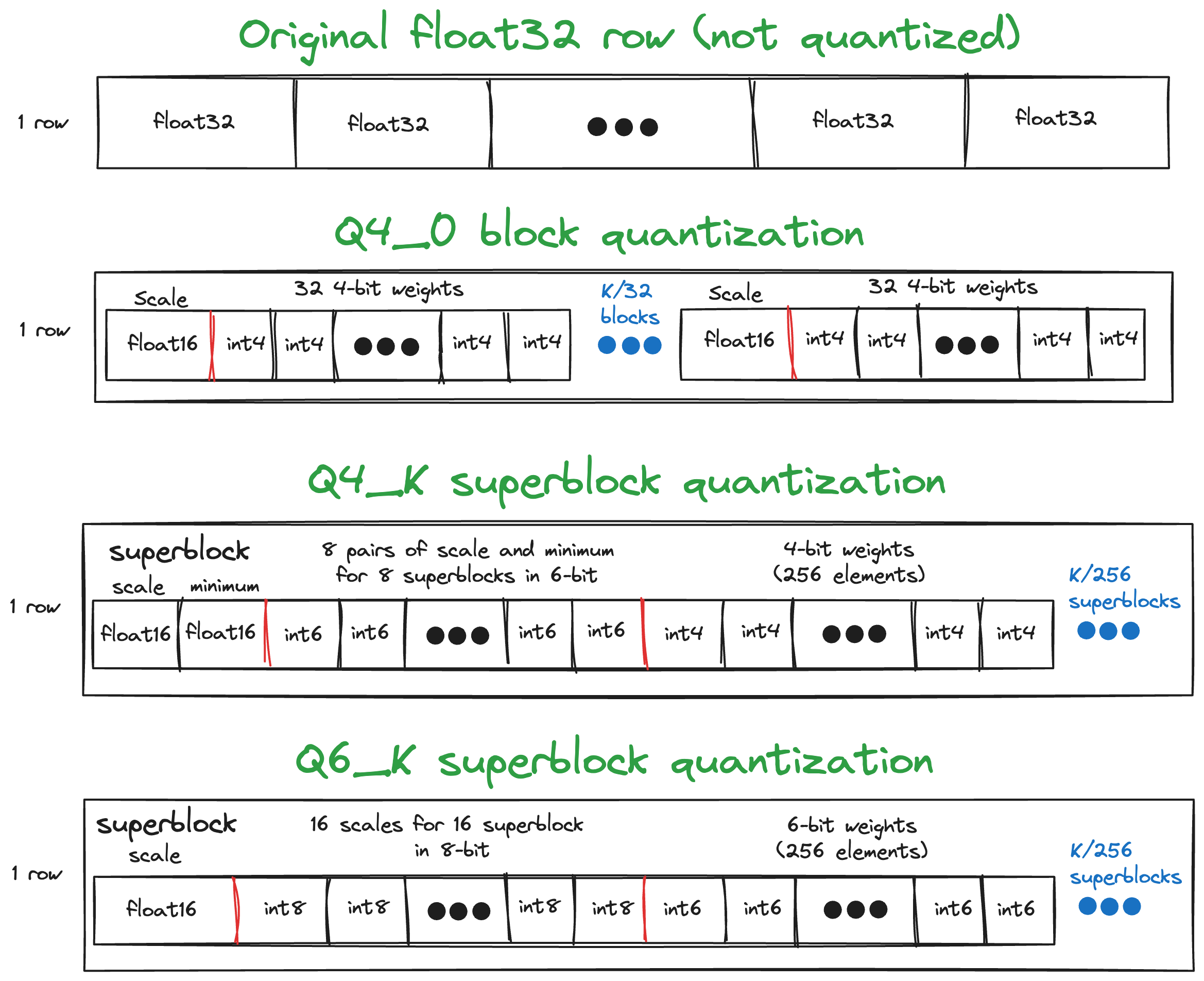
We generally recommend using Q4_K for the best performance and memory use. The higher bit quantization encoding such as Q6_K is useful when we want to trade more memory for higher accuracy.
These advanced quantization approaches are typically only supported in specialized AI frameworks like llama.cpp, but MAX makes them accessible to a much wider range of models very easily. For more details, please refer to llama.cpp here.
The run_pipeline.🔥 comes with various CLI options such as changing the quantization encoding (default is Q4_K) as follows
which outputs
MAX Pipeline Seamless Integration with PyTorch and HuggingFace
MAX Pipeline integrates seamlessly with the PyTorch and HuggingFace tokenizer as well. allowing developers to leverage the powerful tools and libraries from these ecosystems. This integration ensures that you can build and deploy advanced AI models using familiar frameworks while benefiting from the performance and efficiency enhancements provided by MAX.
For example, in Llama2 pipeline, we proceed by installing the transformers package via
and we can use it with the llama2 option
where it generates
MAX Graph Custom Operator
MAX Graph API enables creating custom operators which is useful for writing highly customized graph level operators. Particularly for Llama2, MAX Pipelines has a custom Rotary Embedding (RoPE) operator here. We can invoke such custom operator via
which gives us
To learn more about MAX Graph Custom Operator, please visit our MAX Graph API Tutorial.
Example API
We are iterating rapidly on the MAX Pipelines to deliver best-in-class APIs for MAX developers. Our goal is to make MAX Pipelines more accessible, powerful, and easy to use. One such example can be obtained from here which showcases the capabilities and ease of use of MAX Pipelines, ensuring that developers can quickly integrate and benefit from our advancements. Below is an example to illustrate this
which generates this joke
We can also use the integrated tokenizer and tokenize our prompt with
outputs
By following these simple steps, developers can take full advantage of the advanced features provided by MAX Pipelines. This example API is designed to be intuitive and developer-friendly, allowing for quick integration and immediate productivity.
Next Steps
We are very excited to see what you can accomplish using MAX Pipelines. Please share your creations and innovations with the community. Here are a few options to get you started:
- Explore the various examples and templates provided in the MAX repository.
- Experiment with different quantization formats and tokenizers to optimize your models.
- Utilize the GGUF file format for efficient model storage and deployment.
- Share your projects and experiences on forums, social media, and the Modular AI community.
- Use MAX Pipelines to build state-of-the-art AI models tailored to your specific needs. Deploy your models on various platforms, including macOS, Intel x86, and ARM Graviton cloud-serving infrastructure. Leverage the performance enhancements of the Quantization API to optimize your Generative AI pipelines.
Conclusion
The release of MAX 24.4 is a great progress on the unification of AI development tools. With the introduction of MAX on macOS and MAX Pipelines featuring native support for Generative AI models such as Llama3, developers now have unprecedented capabilities to build and deploy advanced AI models efficiently. This release brings together powerful features like the Quantization API, native GGUF, and tokenizer support, providing a comprehensive toolchain for creating high-performance AI solutions.
Throughout this blog post, we have explored various features of MAX Pipelines and their benefits for Generative AI applications. From running quantized Llama3 models in pure Mojo to leveraging the integrated tokenizer and quantization support, MAX Pipelines offer a robust and flexible framework for AI development.
Key Takeaways for Developers
- Native GGUF Support: Simplifies model storage and deployment with efficient single-file format.
- Integrated Tokenizers: Ensures efficient text preprocessing and seamless integration with Generative AI models.
- Quantization Support: Reduces memory and computational costs, enabling the deployment of large models on local machines.
- Seamless Integration: Works effortlessly with PyTorch and HuggingFace, allowing the use of powerful tools and libraries from these ecosystems.
- Custom Operators: Provides the ability to create highly customized graph-level operators, enhancing model performance and flexibility.
By following the steps and examples provided, developers can take full advantage of the advanced features in MAX Pipelines, ensuring optimal performance and ease of use. Whether you're working on macOS, Intel x86, or ARM Graviton cloud-serving infrastructure, MAX 24.4 empowers you to build state-of-the-art AI models tailored to your specific needs.
We’re excited to see what you build with MAX 24.4 ⚡️ and Mojo 🔥!
- Get started with MAX 24.4.
- Read the MAX ⚡️ docs and the Mojo🔥 manual.
- Learn about the new quantization APIs.
- Explore the MAX pipeline examples on GitHub.
- Join our Discord community.
- Read and subscribe to Modverse Newsletter.
- Read Mojo blog posts, watch developer videos and past live streams.
Until next time! 🔥


