

Ownership is a well-known concept in modern programming languages such as Mojo that aims to provide a safe programming model for memory management while ensuring high performance. This allows programmers to build safe abstractions without the need to manually manage memory, making development more efficient and less error-prone.
In this blog post, we will build an intuitive understanding of how memory works and expand on that foundation to create a simple mental model for the concept of ownership. This post serves as accompanying material for the deep dive on ownership by our CEO, Chris Lattner. Be sure to watch the video as well, which covers how ownership is implemented in Mojo's compiler, providing further insights and technical details.
An intuitive journey through memory management 🎒
To build a simple mental model for ownership, we first need to build an intuitive understanding of how memory works in computing.
Stack vs. heap
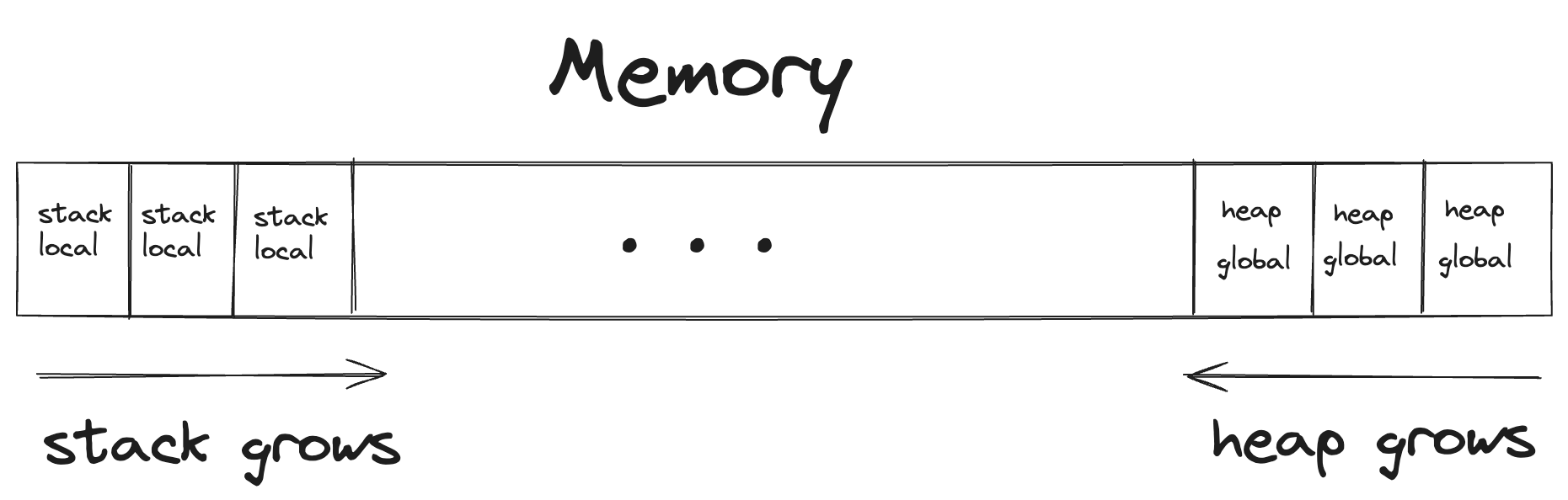
When a program runs, it needs a place to store data. This data is stored in two main areas of memory: the stack and the heap. Understanding the difference between these two is crucial for grasping the concept of ownership.
- Stack: The stack is a region of memory that stores temporary variables created by each function (including the main function). It is managed in a Last-In-First-Out (LIFO) order, meaning that the last variable pushed onto the stack is the first one to be popped off. The stack is very efficient for managing memory because allocating and deallocating variables on the stack is extremely fast. However, the stack is limited in size and scope. It's ideal for storing short-lived, simple data like function parameters, return addresses, and local variables.
- Heap: The heap is a larger pool of memory used for dynamic allocation. Unlike the stack, the heap does not follow a LIFO order. Instead, it allows for flexible and arbitrary memory allocation and deallocation. This makes it suitable for storing data that needs to live for an unpredictable duration or whose size may change. The trade-off is that managing heap memory requires more effort and can be slower due to the overhead of finding and managing free space.
We can visualize the stack and the heap in a simple linear model of memory as follows:
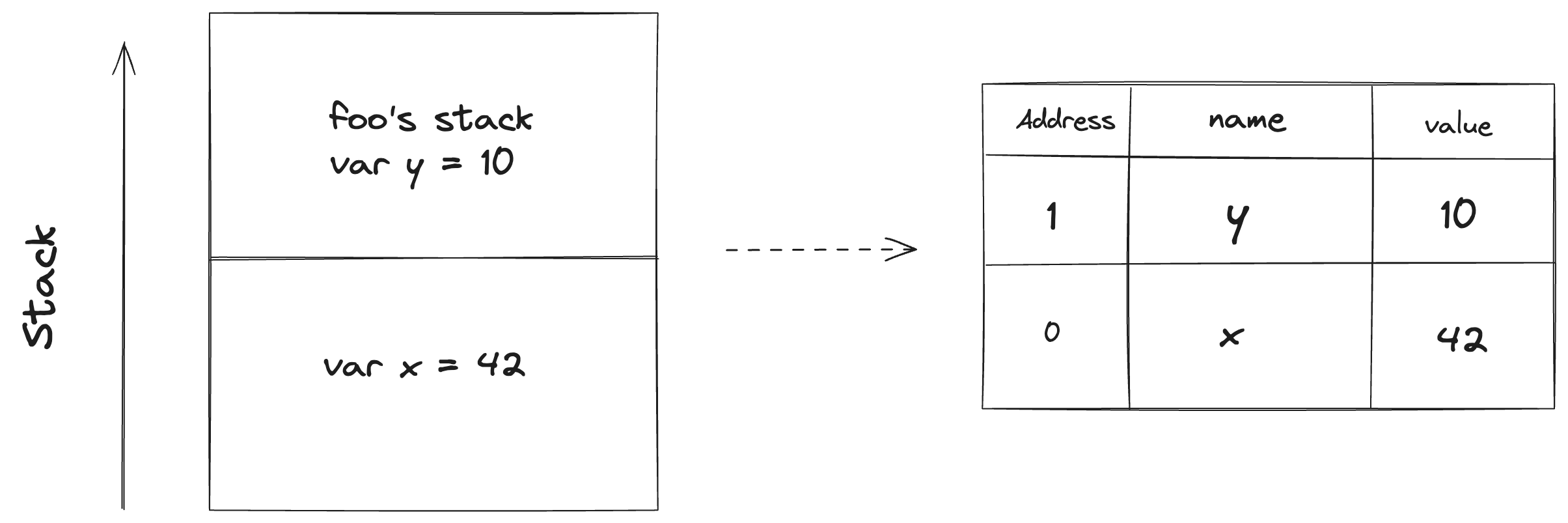
For example, the stack for the following Mojo program looks like:
We can zoom in each block of stack (i.e. stack frame) which includes a table of address, name and value. For simplicity, we do not take care of types and size of each stored value so the y‘s address is 1.
A crucial difference between the stack and the heap is that two functions cannot access each other's stack frames, making the stack local to each function. This local nature ensures that variables stored on the stack are isolated and protected from unintended interference by other functions. In contrast, the heap is globally accessible, allowing functions to share and modify the same dynamically allocated memory. This global accessibility makes the heap suitable for storing data that needs to persist and be shared across various parts of a program. Such global access forms the core of memory management. Two functions can step into each other’s heap memory, causing various issues that we will discuss later, and we will learn how ownership can prevent such memory management problems.
First, let’s see how we can access memory.
How to access memory?
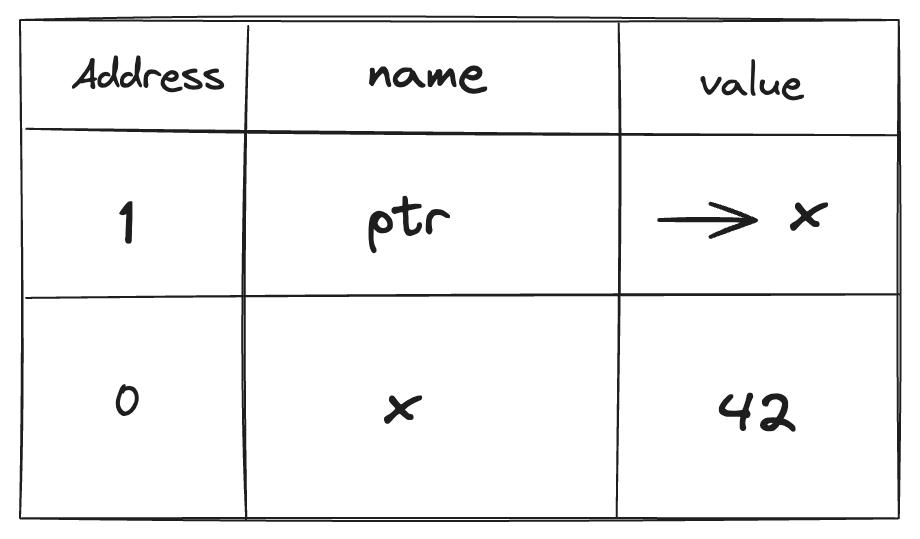
We showed a variable storing a value has an address in memory. In C such address can be found using the address operator &. In the following example, &x returns the address of x in memory which is a (raw) pointer ptr.
To start building our mental model, we will use a Mojo-like pseudocode in this part to construct each piece that will eventually give rise to our mental model.
In this example, Address represents a simple structure holding an address, and RawPointer provides methods to allocate, write, read, and free memory. The main function demonstrates creating a variable x and obtaining its address as a RawPointer. We can visualize the stack as follows where -> x refers to the value of ptr in memory.
How to work with the heap?
So far, we have only worked with the stack. To work with the heap, let’s try to create a String object using our RawPointer. Note that the implementation details of String are not essential for our mental model, so we will skip them.
Looking closer, an instance of our String is created in these steps:
In this example:
- Allocate enough space on the heap for the String object. This is done by calling alloc on a RawPointer.
- Initialize the allocated space with the string "hello, world!". This is done by calling write on the uninitialized pointer.
- Assign the initialized pointer to the variable x, effectively creating a String object with the data stored on the heap.
The final result can be visualized as follows where the value of x is ptr but the actual value of x is the ”hello, world!” stored in heap in binary format (below we also show the ASCII values for clarity):

Note that we also need to manually free the pointed memory after done with x. Next, let’s explore a few critical bugs that can occur with such manual memory access.
What are the critical bugs in manual memory management?
The following are the top two critical bugs that can happen in such manual memory management.
Use-after-free
A use-after-free error occurs when a program continues to use a pointer after the memory it points to has been freed. This can lead to Undefined Behavior (UB), such as program crashes or data corruption.
Double-free
A double-free error happens when a program attempts to free the same memory location more than once. This can lead to Undefined Behavior and potential security vulnerabilities.
We are now ready to build our intuitive mental model for the compiler to catch such mentioned bugs.
How to catch such memory management errors at compile time?
In order to help the compiler catch such errors, we start by including more metadata to our RawPointer representation.
Step 0: Add type parameter to RawPointer
As a statically compiled language, we first can enrich the RawPointer with the type information [T] as follows. Note that we are borrowing the compile-time parameter in square-brackets in Mojo
Adding type information [T] to RawPointer provides several benefits:
- Type Safety: By specifying the type of data the pointer is referencing, the compiler can ensure that only valid operations are performed on the data. This prevents type-related errors and ensures that operations like reading, writing, and freeing memory are type-safe.
- Compile-Time Checks: With type information, the compiler can perform more rigorous compile-time checks. This helps catch potential errors early in the development process, reducing runtime errors and improving the reliability of the code.
- Optimizations: The compiler can use type information to optimize memory access and management. Knowing the exact type of data being referenced allows the compiler to generate more efficient code.
Step 1: Add lifetime parameter to TypedRawPointer[T]
Next, we introduce a lifetime parameter to the TypedRawPointer[T] to track the validity period of pointer usage. This metadata tracks when a pointer is valid or has been freed.
With this, we have the following definitions
Definition 1: A reference is a typed raw pointer with lifetime. (Not be confused by the standard library Reference).
Definition 2: A reference is safe if its lifetime is in a valid state.
We should note that whenever we are done with checking lifetime, we can erase it (and its type too) to get to the underlying RawPointer.

With these added metadata, let’s go back and examine if they are enough to catch either use-after-free or double-free errors.
Lifetime analysis prevents double-free
Here is an example of how lifetime analysis prevents double-free errors.
First, memory heap is allocated. The allocation returns a raw pointer to an uninitialized memory. Next, a reference Ref is established and marks its lifetime as IsAlive. Finally, the data is written to the underlying memory with a variable x coming into existence.
The last line double_free(x) when expanded it becomes:
Visually it looks like:
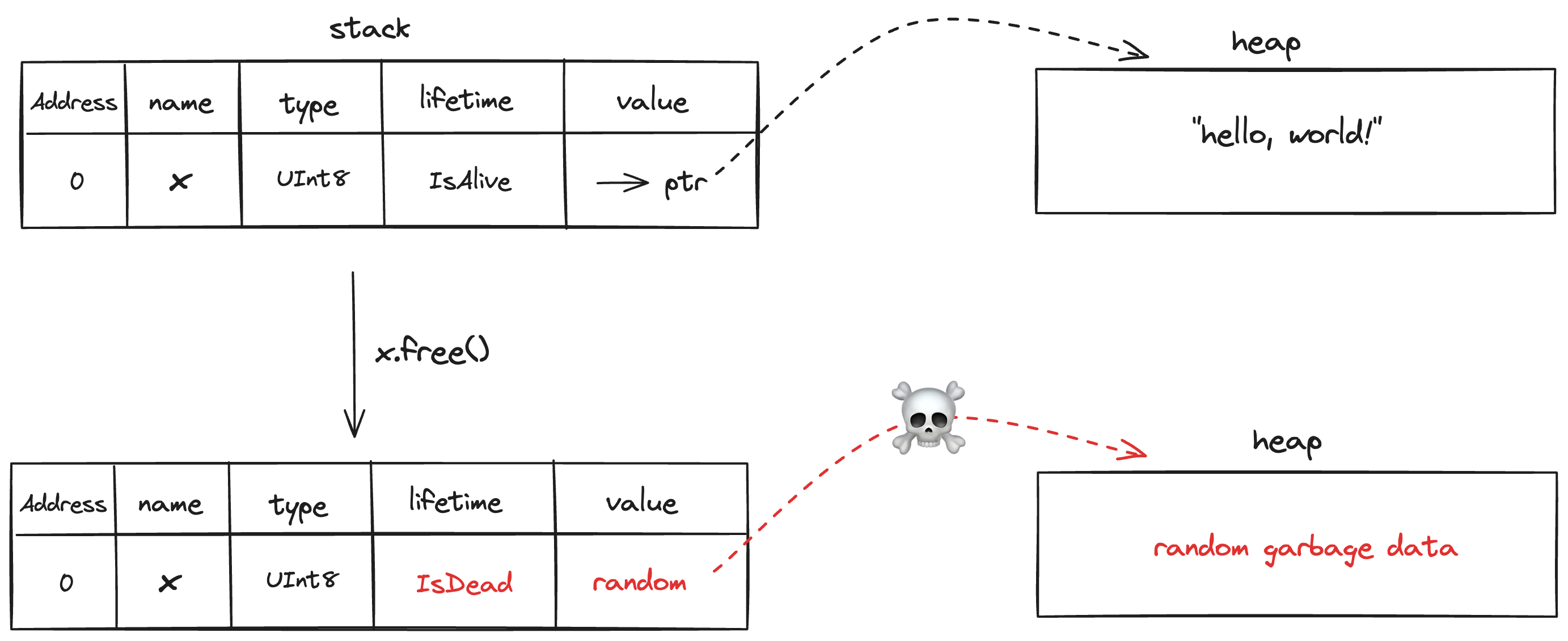
By using lifetime parameters, we can ensure that memory is only freed once, preventing double-free errors.
Can lifetime analysis alone also prevent use-after-free?
Let's see if lifetime analysis alone can prevent use-after-free errors.
In the above example, the lifetime analysis ensures that the reference x is valid only within a specific time frame. After x.free(), the lifetime of the reference x is marked as IsDead, indicating that it should not be used. However, lifetime alone does not prevent other functions or parts of the code from using the reference x incorrectly (Lack of Exclusive Ownership). In the use_after_free function, x.write(tmp) is attempted even though x is already freed. Therefore, the lifetime system alone does not enforce exclusive access or prevent this usage. Lifetimes track validity but do not manage the state of the memory or enforce rules about how it can be accessed after certain operations. More metadata is needed to bake the ownership model which is necessary to ensure that once x.free() is called, no other references can access or modify x.
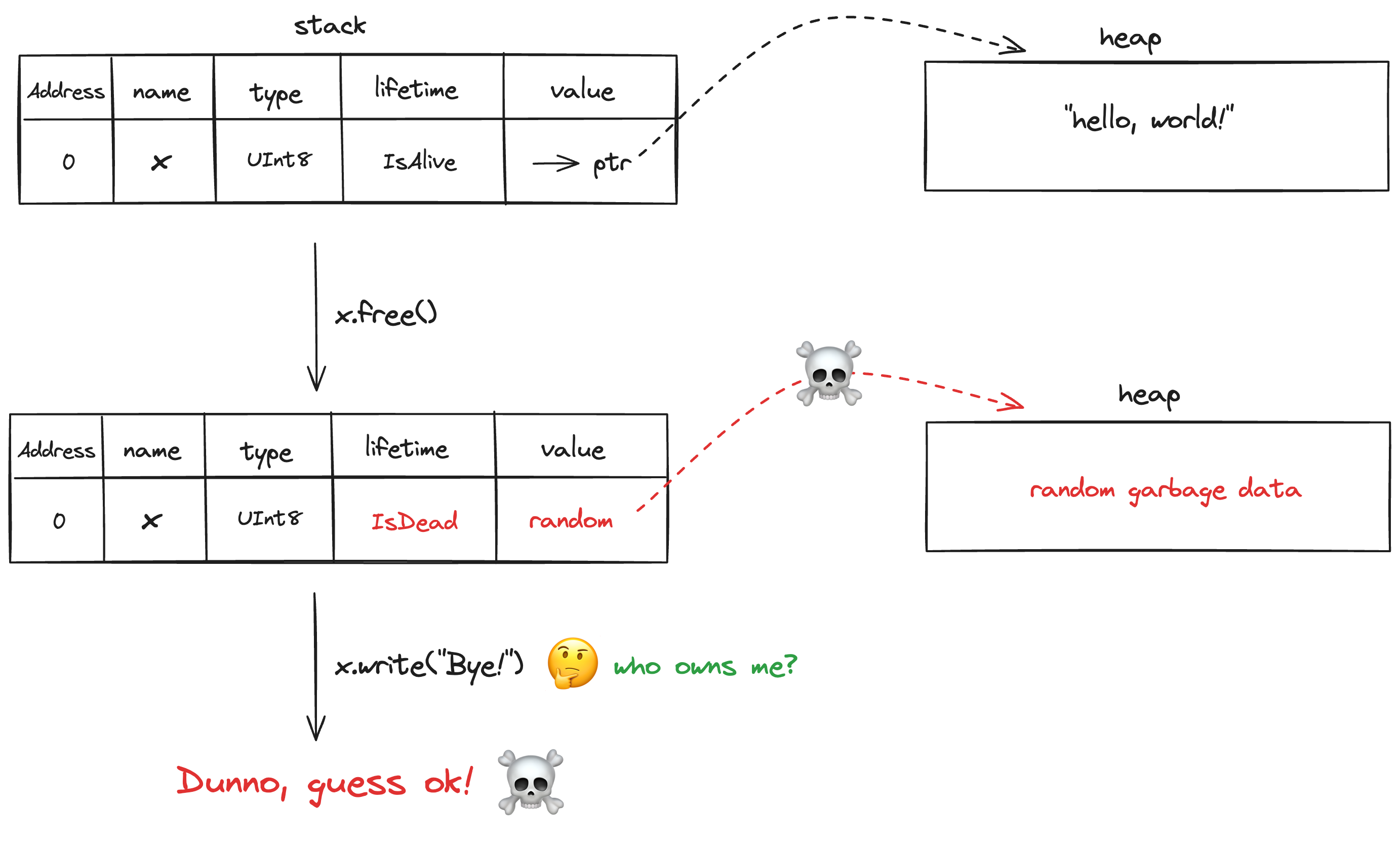
Looking at the above diagram, we might ask what if we disallow the use of x after its lifetime is marked IsDead? In that case, we will enter the dataflow analysis which keeps track of what value is in use, can or can not be used. This idea basically leads to the concept of ownership that we will talk about next.
Step 2: Specify ownership
To further enhance the safety of our memory management, we introduce ownership parameter. The goal of ownership is to enforce exclusive access and state management for memory references:
Such ownership parameter introduces a new layer of metadata that the compiler can use to enforce strict memory management rules:
- Exclusive Ownership: UniqueRef ensures that there is only one reference to the allocated memory at any given time. This prevents multiple references from accessing and potentially modifying the same memory simultaneously, avoiding race conditions and ensuring data integrity.
- Immutable Reference and Mutable References: ImmutableRef and MutableRef allow for controlled access to memory, ensuring that certain references can only read (immutable) while others can modify (mutable). This helps in maintaining the integrity of data by restricting unintended modifications.
- Invalid State: InvalidRef represents a state where the memory has been freed and should not be accessed after. This helps in catching use-after-free errors by marking references as invalid after the memory is deallocated.
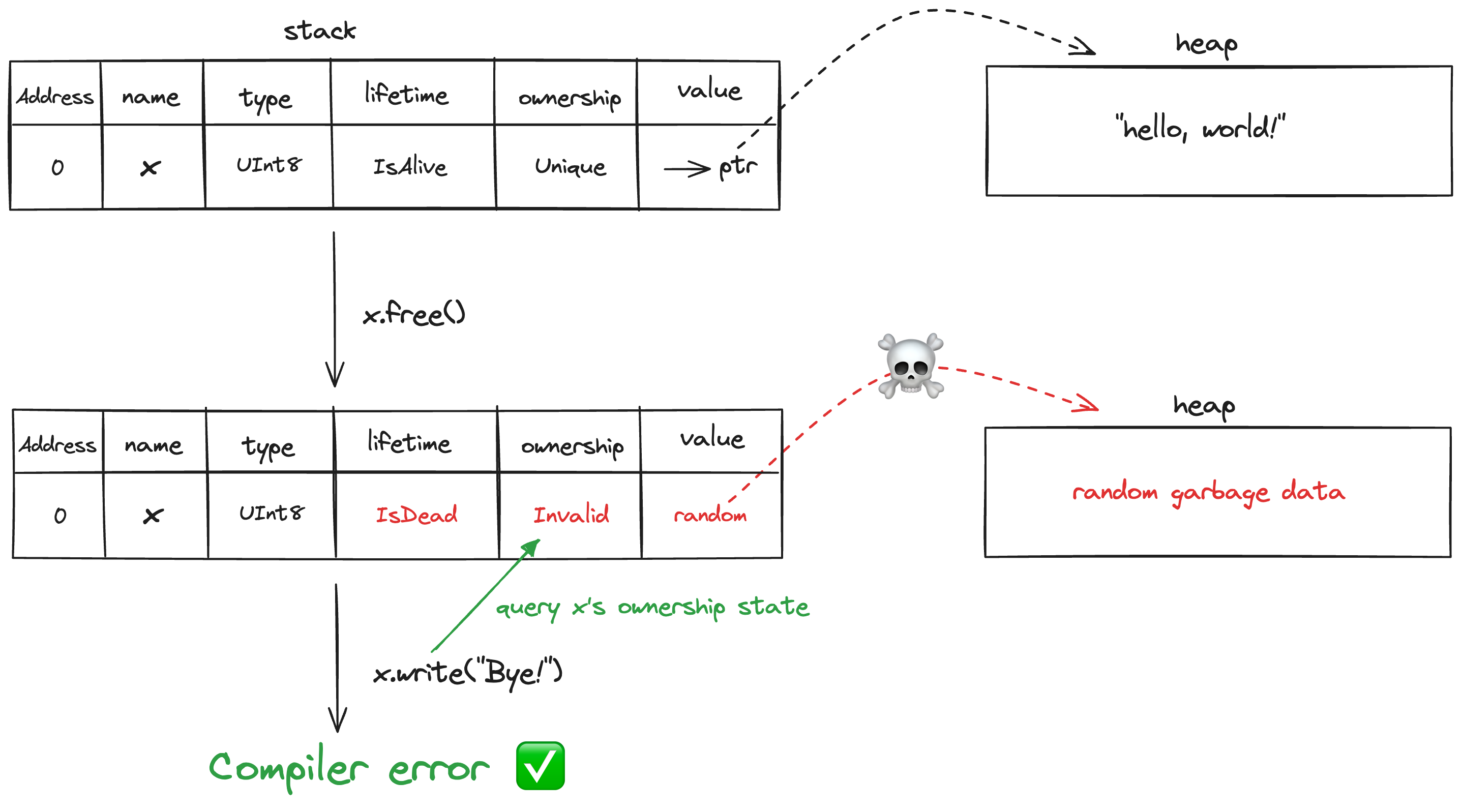
Let’s have a look at the use-after-free case but now with ownership included
The use-after-free error is prevented by the UniqueRef type through the following mechanisms:
- Exclusive Ownership: UniqueRef ensures that x is the only reference to the allocated memory. Once x.free() is called, the memory is marked as freed, and the unique reference is invalidated i.e. turns into InvalidRef[UInt8, IsDead] vs. in the previous step 1, it was Ref[UInt8, IsDead] which didn’t have enough information to help the compiler reason about its ownership state.
- Compile-Time Checks: When use_after_free(x) is called after x.free(), the compiler checks the ownership state of x. Since x has been freed, it no longer holds a valid UniqueRef. The compiler can detect this invalid state and generate a compile-time error.
- Lifetime and Ownership Enforcement: The combination of lifetime and ownership parameters ensures that the reference x cannot be used after it has been freed. This prevents any attempt to write to or read from the memory through x after the free operation.
Conclusion
In this first part of the series on ownership, we have developed a mental model of how memory works. We talked about the stack being used for local variables and function calls, while the heap is used for dynamic memory allocation. The stack is fast and local, whereas the heap is flexible and globally accessible which can cause critical memory errors such as use-after-free and double-free that can lead to Undefined Behavior and security vulnerabilities.
Later, we tried to look through the lens of the compiler and develop an intuitive understanding of how adding type and lifetime parameters to RawPointer helps the compiler catch errors related to type safety and memory validity. Last but not least, we introduced the ownership parameter that enforces exclusive access and state management, preventing use-after-free and double-free errors. By incorporating these concepts into our mental model, we enable the compiler to catch memory management errors at compile time, ensuring safer and more efficient memory usage. In the next blog post, we will dive deep into ownership in Mojo. We end this part with the following quote from the talk.
“Ownership is a joint responsibility of type-checker and (dataflow) lifetime analysis.” - Chris Lattner
Additional resources:
- Get started with Mojo
- Official Mojo manual
- Join our Discord community
- Contribute to discussions on the Mojo and MAX GitHub
Report feedback, including issues on our Mojo and MAX GitHub tracker.
Until next time! 🔥


