
.jpeg)
Answering the question of whether CUDA is “good” is much trickier than it sounds. Are we talking about its raw performance? Its feature set? Perhaps its broader implications in the world of AI development? Whether CUDA is “good” depends on who you ask and what they need. In this post, we’ll evaluate CUDA from the perspective of the people who use it day-in and day-out—those who work in the GenAI ecosystem:
- For AI engineers who build on top of CUDA, it’s an essential tool, but one that comes with versioning headaches, opaque driver behavior, and deep platform dependence.
- For AI engineers who write GPU code for NVIDIA hardware, CUDA offers powerful optimization but only by accepting the pain necessary to achieve top performance.
- For those who want their AI workloads to run on GPU’s from multiple vendors, CUDA is more an obstacle than a solution.
- Then there’s NVIDIA itself—the company that has built its fortune around CUDA, driving massive profits and reinforcing their dominance over AI compute.
So, is CUDA “good?” Let’s dive into each perspective to find out! 🤿
AI Engineers
Many engineers today are building applications on top of AI frameworks—agentic libraries like LlamaIndex, LangChain, and AutoGen—without needing to dive deep into the underlying hardware details. For these engineers, CUDA is a powerful ally. Its maturity and dominance in the industry bring significant advantages: most AI libraries are designed to work seamlessly with NVIDIA hardware, and the collective focus on a single platform fosters industry-wide collaboration.
However, CUDA’s dominance comes with its own set of persistent challenges. One of the biggest hurdles is the complexity of managing different CUDA versions, which can be a nightmare. This frustration is the subject of numerous memes:

This isn’t just a meme—it’s a real, lived experience for many engineers. These AI practitioners constantly need to ensure compatibility between the CUDA toolkit, NVIDIA drivers, and AI frameworks. Mismatches can cause frustrating build failures or runtime errors, as countless developers have experienced firsthand:
"I failed to build the system with the latest NVIDIA PyTorch docker image. The reason is PyTorch installed by pip is built with CUDA 11.7 while the container uses CUDA 12.1." (github.com)
or:
"Navigating Nvidia GPU drivers and CUDA development software can be challenging. Upgrading CUDA versions or updating the Linux system may lead to issues such as GPU driver corruption." (dev.to)
Sadly, such headaches are not uncommon. Fixing them often requires deep expertise and time-consuming troubleshooting. NVIDIA's reliance on opaque tools and convoluted setup processes deters newcomers and slows down innovation.
In response to these challenges, NVIDIA has historically moved up the stack to solve individual point-solutions rather than fixing the fundamental problem: the CUDA layer itself. For example, it recently introduced NIM (NVIDIA Inference Microservices), a suite of containerized microservices aimed at simplifying AI model deployment. While this might streamline one use-case, NIM also abstracts away underlying operations, increasing lock-in and limiting access to the low-level optimization and innovation key to CUDA's value proposition.
While AI engineers building on top of CUDA face challenges with compatibility and deployment, those working closer to the metal—AI model developers and performance engineers—grapple with an entirely different set of trade-offs.
AI Model Developers and Performance Engineers
For researchers and engineers pushing the limits of AI models, CUDA is simultaneously an essential tool and a frustrating limitation. For them, CUDA isn’t an API; it’s the foundation for every performance-critical operation they write. These are engineers working at the lowest levels of optimization, writing custom CUDA kernels, tuning memory access patterns, and squeezing every last bit of performance from NVIDIA hardware. The scale and cost of GenAI demand it. But does CUDA empower them, or does it limit their ability to innovate?
Despite its dominance, CUDA is showing its age. It was designed in 2007, long before deep learning—let alone GenAI. Since then, GPUs have evolved dramatically, with Tensor Cores and sparsity features becoming central to AI acceleration. CUDA’s early contribution was to make GPU programming easy, but it hasn’t evolved with modern GPU features necessary for transformers and GenAI performance. This forces engineers to work around its limitations just to get the performance their workloads demand.
CUDA doesn’t do everything modern GPUs can do
Cutting-edge techniques like FlashAttention-3 (example code) and DeepSeek’s innovations require developers to drop below CUDA into PTX—NVIDIA’s lower-level assembly language. PTX is only partially documented, constantly shifting between hardware generations, and effectively a black box for developers.
More problematic, PTX is even more locked to NVIDIA than CUDA, and its usability is even worse. However, for teams chasing cutting-edge performance, there’s no alternative—they’re forced to bypass CUDA and endure significant pain.
Tensor Cores: Required for performance, but hidden behind black magic
Today, the bulk of an AI model’s FLOPs come from “Tensor Cores”, not traditional CUDA cores. However, programming Tensor Cores directly is no small feat. While NVIDIA provides some abstractions (like cuBLAS and CUTLASS), getting the most out of GPUs still requires arcane knowledge, trial-and-error testing, and often, reverse engineering undocumented behavior. With each new GPU generation, Tensor Cores change, yet the documentation is dated. This leaves engineers with limited resources to fully unlock the hardware’s potential.
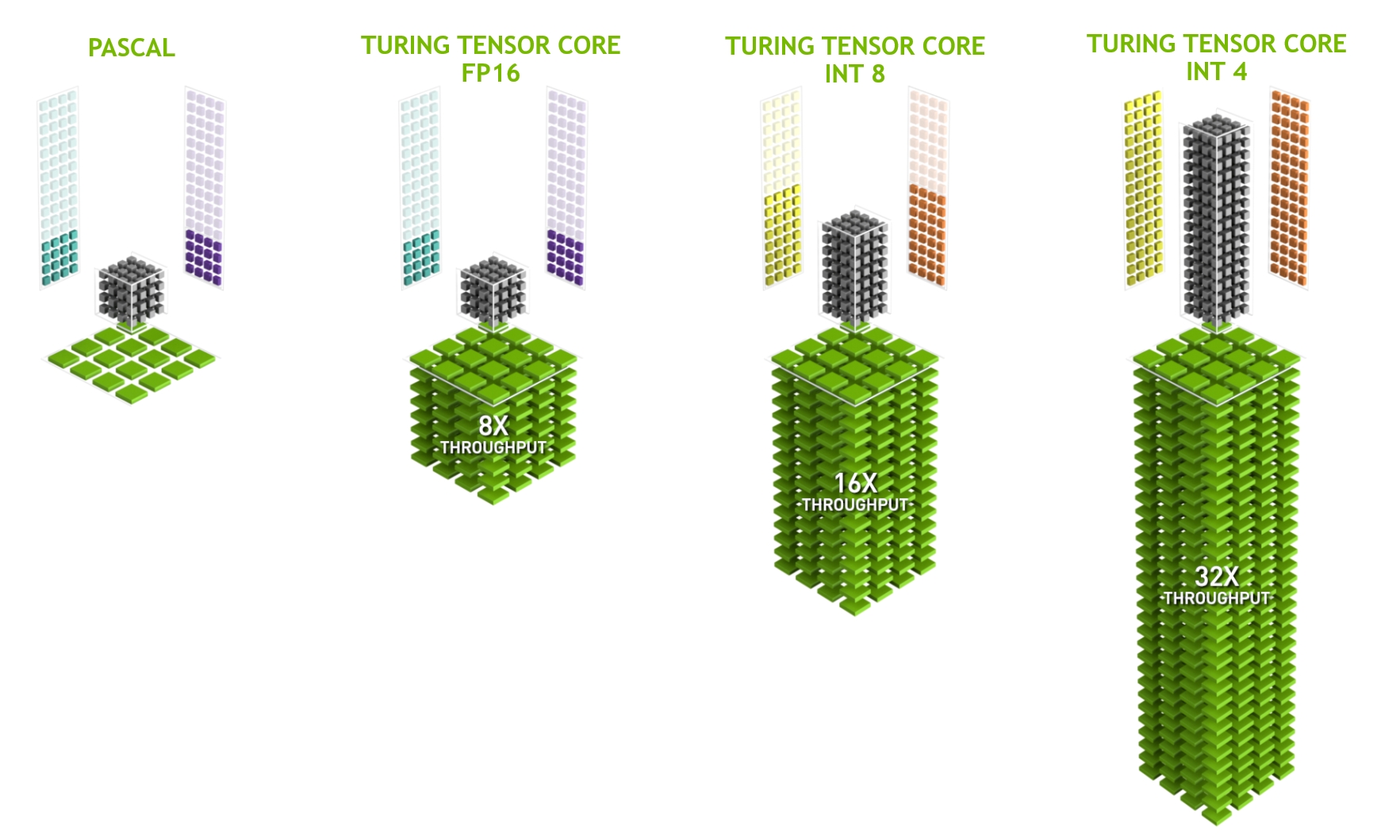
AI is Python, but CUDA is C++
Another major limitation is that writing CUDA fundamentally requires using C++, while modern AI development is overwhelmingly done in Python. Engineers working on AI models and performance in PyTorch don’t want to switch back and forth between Python and C++—the two languages have very different mindsets. This mismatch slows down iteration, creates unnecessary friction, and forces AI engineers to think about low-level performance details when they should be focusing on model improvements. Additionally, CUDA's reliance on C++ templates leads to painfully slow compile times and often incomprehensible error messages.

These are the challenges you face if you’re happy to develop specifically for NVIDIA hardware. But what if you care about more than just NVIDIA?
Engineers and Researchers Building Portable Software
Not everyone is happy to build software locked to NVIDIA’s hardware, and the challenges are clear. CUDA doesn’t run on hardware from other vendors (like the supercomputer in our pockets), and no alternatives provide the full performance and capabilities CUDA provides on NVIDIA hardware. This forces developers to write their AI code multiple times, for multiple platforms.
In practice, many cross-platform AI efforts struggle. Early versions of TensorFlow and PyTorch had OpenCL backends, but they lagged far behind the CUDA backend in both features and speed, leading most users to stick with NVIDIA. Maintaining multiple code paths—CUDA for NVIDIA, something else for other platforms—is costly, and as AI rapidly progresses, only large organizations have resources for such efforts.
The bifurcation CUDA causes creates a self-reinforcing cycle: since NVIDIA has the largest user base and the most powerful hardware, most developers target CUDA first, and hope that others will eventually catch up. This further solidifies CUDA’s dominance as the default platform for AI.
👉 We’ll explore alternatives like OpenCL, TritonLang, and MLIR compilers in our next post, and come to understand why these options haven’t made a dent in CUDA's dominance.
Is CUDA Good for NVIDIA Itself?
Of course, the answer is yes: the “CUDA moat” enables a winner-takes-most scenario. By 2023, NVIDIA held ~98% of the data-center GPU market share, cementing its dominance in the AI space. As we've discussed in previous posts, CUDA serves as the bridge between NVIDIA’s past and future products, driving the adoption of new architectures like Blackwell and maintaining NVIDIA's leadership in AI compute.
However, legendary hardware experts like Jim Keller argue that "CUDA’s a swamp, not a moat,” making analogies to the X86 architecture that bogged Intel down.

How could CUDA be a problem for NVIDIA? There are several challenges.
CUDA's usability impacts NVIDIA the most
Jensen Huang famously claims that NVIDIA employs more software engineers than hardware engineers, with a significant portion dedicated to writing CUDA. But the usability and scalability challenges within CUDA slow down innovation, forcing NVIDIA to aggressively hire engineers to fire-fight these issues.
CUDA’s heft slows new hardware rollout
CUDA doesn’t provide performance portability across NVIDIA’s own hardware generations, and the sheer scale of its libraries is a double-edged sword. When launching a new GPU generation like Blackwell, NVIDIA faces a choice: rewrite CUDA or release hardware that doesn’t fully unleash the new architecture’s performance. This explains why performance is suboptimal at launch of each new generation. Such expansion of CUDA’s surface area is costly and time-consuming.
The Innovator’s Dilemma
NVIDIA’s commitment to backward compatibility—one of CUDA’s early selling points—has now become “technical debt” that hinders their own ability to innovate rapidly. While maintaining support for older generations of GPUs is essential for their developer base, it forces NVIDIA to prioritize stability over revolutionary changes. This long-term support costs time, resources, and could limit their flexibility moving forward.
Though NVIDIA has promised developers continuity, Blackwell couldn't achieve its performance goals without breaking compatibility with Hopper PTX—now some Hopper PTX operations don’t work on Blackwell. This means advanced developers who have bypassed CUDA in favor of PTX may find themselves rewriting their code for the next-generation hardware.
Despite these challenges, NVIDIA’s strong execution in software and its early strategic decisions have positioned them well for future growth. With the rise of GenAI and a growing ecosystem built on CUDA, NVIDIA is poised to remain at the forefront of AI compute and has rapidly grown into one of the most valuable companies in the world.
Where Are the Alternatives to CUDA?
In conclusion, CUDA remains both a blessing and a burden, depending on which side of the ecosystem you’re on. Its massive success drove NVIDIA’s dominance, but its complexity, technical debt, and vendor lock-in present significant challenges for developers and the future of AI compute.
With AI hardware evolving rapidly, a natural question emerges: Where are the alternatives to CUDA? Why hasn’t another approach solved these issues already? In Part 5, we’ll explore the most prominent alternatives, examining the technical and strategic problems that prevent them from breaking through the CUDA moat. 🚀
–Chris


