

In the field of natural language processing (NLP), semantic search focuses on understanding the context and intent behind queries, going beyond mere keyword matching to provide more relevant and contextually appropriate results. This approach relies on advanced embedding models to convert text into high-dimensional vectors, capturing the complex semantics of language. In this blog post, we will use Amazon Multilingual Counterfactual Dataset (AMCD) which comprises sentences from Amazon customer reviews annotated for counterfactual detection (CFD) in a binary classification task. Counterfactual statements refer to hypothetical scenarios that have not occurred or are impossible to occur. Such statements are typically recognized as having the structure – If p were true, q would also be true, where both the antecedent (p) and the consequent (q) are understood or presumed to be untrue. For instance, a review stating "If this camera had a better lens, my photos would be perfect" suggests a desired improvement (a better lens) that is currently absent, impacting the outcome (perfect photos).
Our classifier will employ the bge-base-en-v1.5 model within the MAX Engine which has 768 embedding dimensions. The BGE model is distinguished as one of the leading text embedding models on the MTEB leaderboard characterized by its minimal disk size of 416MB and available variants with 768 and 1024 embedding dimensions. Furthermore, we will leverage a vector database to store embeddings generated from the training dataset, simulating real-world conditions for batched inference processing. During inference, we will identify the top 10 most similar reviews (using cosine similarity) and assign probabilities to test queries. Subsequently, we will evaluate the classifier's effectiveness through metrics such as accuracy, F1 score, precision, and recall, applying a 0.5 cutoff threshold. Ultimately, we will contrast the performance of MAX Engine with PyTorch and ONNX runtime across various batch sizes, illustrating that
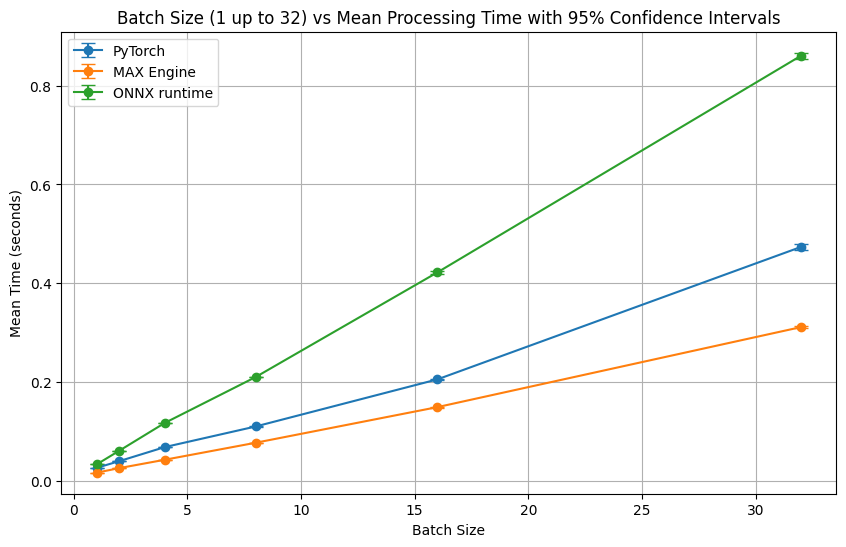
- For small batch sizes on CPU, MAX Engine outperforms PyTorch and ONNX runtime by up to 1.6 and 2.8 times, respectively.
- With large batch sizes on CPU, MAX Engine outperforms PyTorch and ONNX runtime by 2 and 1.8 times, respectively.
To install MAX, please check out Get started with MAX Engine. Also have a look at Getting Started with MAX Developer Edition in case you missed it.
The code for this blog post is available in our GitHub repository. The MAX version for this blog is 24.1.1 (0ab415f7).
Dataset and input tokenizer
Let’s first examine the data in Amazon Multilingual Counterfactual Dataset (AMCD)
The dataframe consists of two columns: sentence (from Amazon customer review) and is_counterfactual (the label) and a total of 4018 samples.
For example:

Next we tokenize all the input sentences in data as follows
With the inputs tokenized, we are now ready to proceed to inference and create sentence embeddings.
MAX Engine inference
In this blog post, we will utilize the ONNX version of the model, available on HuggingFace. We can obtain use the following command (ensure you have Git LFS installed)
The ONNX model is located at bge-base-en-v1.5/onnx/model.onnx.
Below, we create a session object and load the model into maxmodel. We also examine the input and output tensors, noting their names, shapes, and data types:
The model has three input tensors — input_ids, attention_mask, and token_type_ids — and one output tensor, last_hidden_state:
The model's pooling configuration file is as follows which we will use later to accurately obtain our sentence embeddings.
Optional: Convert to ONNX using optimum
Another notable option is the conversion of models to the ONNX format using the optimum package which can be done through its command-line-interface (CLI).
Note that converting to ONNX offers benefits like framework interoperability across different platforms. For instance, to convert the BAAI/bge-base-en-v1.5 model to ONNX:
Sentence embeddings
To enhance efficiency, especially with large datasets, we batch the input sentences before embedding. This approach not only accelerates the processing but also helps manage memory usage more effectively.
Here, in each batch we simply call maxmodel.execute and iterate on the training data until all sentences are embedded.
which outputs
After obtaining the embeddings, they can be utilized for various NLP tasks, such as semantic similarity, clustering, or as input features for machine learning models. In the next section, we will store them in a vector database for semantic search.
Using a Vector Database
Vector databases excel in managing and querying high-dimensional data, making them ideal for storing embeddings. We chose ChromaDB which is an embedded vector database and is known for its efficiency and straightforward usage, particularly fitting for small to medium-sized applications. ChromaDB stands out due to its fast querying capabilities and lightweight nature.
To start, we create a client and a collection to store our embeddings as follows
Search in Vector Database collection
To demonstrate the practical application, we query the database using a test sentence. After tokenizing this sentence and generating its embedding, we search the vector database for the most similar entries, using cosine similarity to identify and return the top 10 most similar items. Cosine similarity is particularly effective for embeddings because it focuses on the orientation of vectors rather than their magnitude. Finally, we assign a probability by normalizing the count of positive is_counterfactual results from the top 10 queries, leveraging cosine similarity.
which outputs
Assess test accuracy, F1-score, precision and recall
We evaluate our model on a test dataset using common metrics.
- Accuracy provides a general sense of performance
- F1-score balances precision and recall
- Precision measures the model's exactness and
- Recall assesses its completeness
which outputs
Comparing MAX Engine performance against PyTorch eager and ONNX runtime
Recall that to efficiently compute all sentence embeddings, we processed them in batches, using a batch size of 128. This batching is particularly important in data intensive scenarios for optimizing resource utilization and processing speed. Consequently, we aim to compare the performance of MAX Engine against PyTorch and ONNX runtime across various batch sizes to understand their respective efficiencies in handling batched data.
To make a compelling comparison between MAX Engine, PyTorch and ONNX runtime, we meticulously selected a range of batch sizes and for better visualization, we divided them up into two categories of
- smaller batch sizes: 1 up to 32 and
- larger batch sizes: 64 up to 4096
These wide arrays allow us to observe the performance scalability and efficiency of each framework under different load conditions. The runtime for each batch size is measured, offering a clear picture of how each framework handles varying volumes of data. This evaluation is crucial for developers and engineers to make informed decisions about the tools and frameworks best suited for their specific NLP tasks, especially in resource-intensive scenarios such as working with large datasets. For completeness, runtime measurements were done on an AWS c5.12xlarge instance.
Now we use the PyTorch, ONNX model and MAX Engine model individually and plot their performance.
This analysis revealed that for smaller batch sizes (1 up to 32), MAX Engine can be up to 1.6 times faster than PyTorch and is up to 2.8 times faster than ONNX runtime for batch inference.
And for larger batch sizes (64 up to 4096), MAX Engine can be up to 2 and 1.8 times faster than PyTorch and ONNX runtime, respectively. This is showcasing MAX Engine efficiency in handling high-volume data processing tasks.
which shows

Conclusion
We have illustrated the application of MAX Engine with a pre-trained model for counterfactual binary classification, demonstrating the process of storing embeddings in a vector database suited for inference. Furthermore, our comparison between MAX Engine and PyTorch across various batch sizes has revealed that MAX Engine can achieve up to 1.6 and 2.8 times the speed up against PyTorch and ONNX runtime for varying small batch sizes when running on a CPU, and is 2 and 1.8 times faster against PyTorch and ONNX runtime on large batch sizes, respectively. This efficiency gain highlights MAX Engine's potential to significantly enhance processing speed and resource utilization in large-scale NLP tasks.
Additional resources:
- Get started with downloading MAX
- Download and run MAX examples on GitHub
- Head over to the MAX docs to learn more about MAX Engine APIs and Mojo programming manual
- Join our Discord community
- Contribute to discussions on the Mojo and MAX GitHub
Report feedback, including issues on our Mojo and MAX GitHub tracker.
Until next time!🔥


