.png)

We’re excited to announce MAX 25.2, a major update that unlocks industry-leading performance on the largest language models–built from the ground up without CUDA*.
This release builds on the momentum from MAX 25.1 released just a month ago, and delivers critical features to power faster, more responsive, and more customizable GenAI deployments at scale:
- State of the art H100 and H200 performance: with support for more than 500 GenAI models.
- Multi-GPU support: seamlessly run large LLMs that exceed single-GPU memory limits.
- Enhanced LLM Serving: improved scheduling, batching, and caching further improves TCO and performance–MAX is now 12% faster than vLLM 0.8 on Sonnet benchmarks with the same numerics.
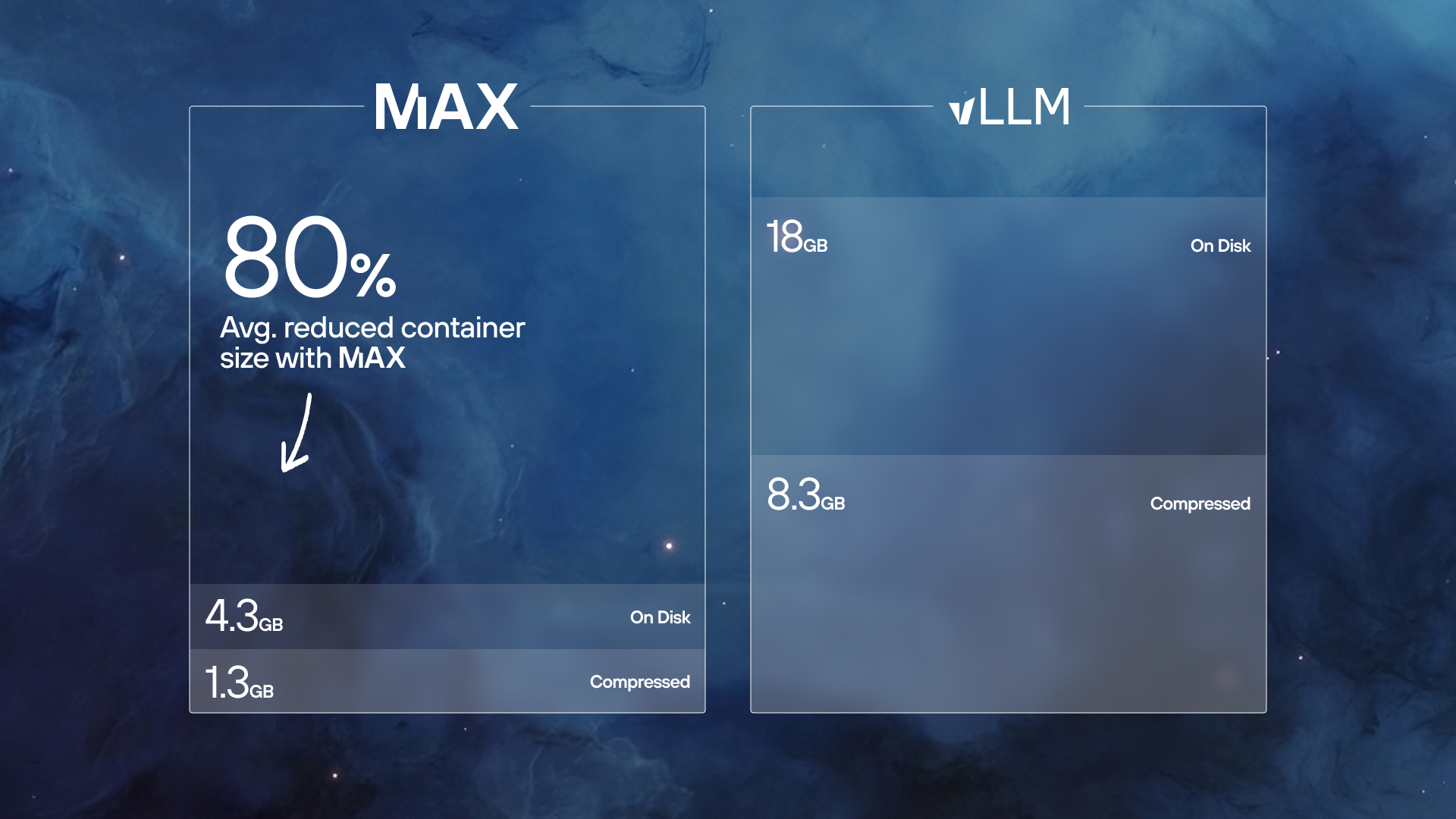
- Ultra-slim containers for rapid deployment “without CUDA:” 80% smaller than NVIDIA containers–ideal for faster deployments to production environments.
- Unlock GPU Programming with Mojo 🔥: MAX allows you to write custom, high-performance GPU code in Mojo with direct access to NVIDIA GPUs.
- Advanced features: including GPTQ quantization to run the biggest models efficiently.
MAX 25.2 is a milestone in our mission to build a CUDA-free GenAI model inference platform that gives you uncompromising performance and control on a single heterogeneous stack.
👉 Dive into what’s new and get started today!
*MAX Requires the NVIDIA hardware driver for GPU access.
Multi-GPU + H100/H200 support: run massive LLMs with industry-leading performance
This release's headline feature is full multi-GPU support on NVIDIA H100 and H200s, allowing you to run even larger language models with incredible performance. You can now deploy Llama-3.3-70B-Instruct across multiple GPUs directly from MAX Builds.
After installing max-pipelines, try running a 70B parameter model in bfloat16 on 4 GPUs with a simple command:
We rebuilt the entire AI stack from the bottom up–including all of the software that runs on the GPU–in order to bring a simple “it just works” experience to AI, without removing your power and control over AI. To do this, we implemented all of the GenAI GPU algorithms for the complex H100/H200 architecture, with performance that meets and beats the NVIDIA libraries. You don’t need to worry about this, but it does mean you can forget about CUDA version mismatches and its legacy weight!
More than 500 preconfigured GenAI models
But that's not all! We've also expanded our supported model architectures to include:
- Qwen2ForCausalLM, including Qwen/Qwen2.5-7B-Instruct and Qwen/QwQ-32B,
- Microsoft Phi3ForCausalLM, including microsoft/Phi-3.5-mini-instruct and microsoft/phi-4,
- ExaoneForCausalLM, including EXAONE-3.0-7.8B-Instruct and EXAONE-3.5-2.4B-Instruct,
- additional architectures like OlmoForCausalLM from AllenAI and GraniteForCausalLM from IBM,
- and many more!
The MAX Builds repository now hosts over 500 preconfigured MAX models ready for immediate deployment. Whatever your AI use case, we've got you covered!

Beyond model generality, MAX transparently supports many advanced features. One example is GPTQ quantization for models–just specify the quantized weights, and MAX handles the rest. For Llama 3.1 70B, this reduces the total memory consumption of this model from about 140 GB to 35 GB, making MAX even more accessible on memory-limited devices. You can use max-pipelines to run Llama 3.1 70B using int4-quantized GPTQ weights:
Please see the detailed release notes for more details on this and other cool technology.
LLM Serving improvements
This release builds on our LLM serving capabilities to add:
- Prefix cache-aware batch scheduling: The scheduler can now create larger batches when many prompt tokens are cached, improving throughput by up to 10% in some benchmarks.
- In-flight batching: allowing token generation requests to be scheduled alongside context encoding, reducing inter-token latency.
- Copy-on-write KV blocks: integrated into Paged Attention with Prefix Caching, improving performance by optimizing cache hits.
These improvements give you better performance and capabilities that continue to "just work."
Slim Docker container: deploy faster than ever
Speed matters not just in inference but also in deployment. Because MAX models are built without CUDA, we don't have to carry its weight. Our new slim Docker container slashes the footprint of the serving container to just 1.3 GB compressed, enabling lightning-fast deployments even for your largest models. Get your AI applications up and running in record time without compromising performance.
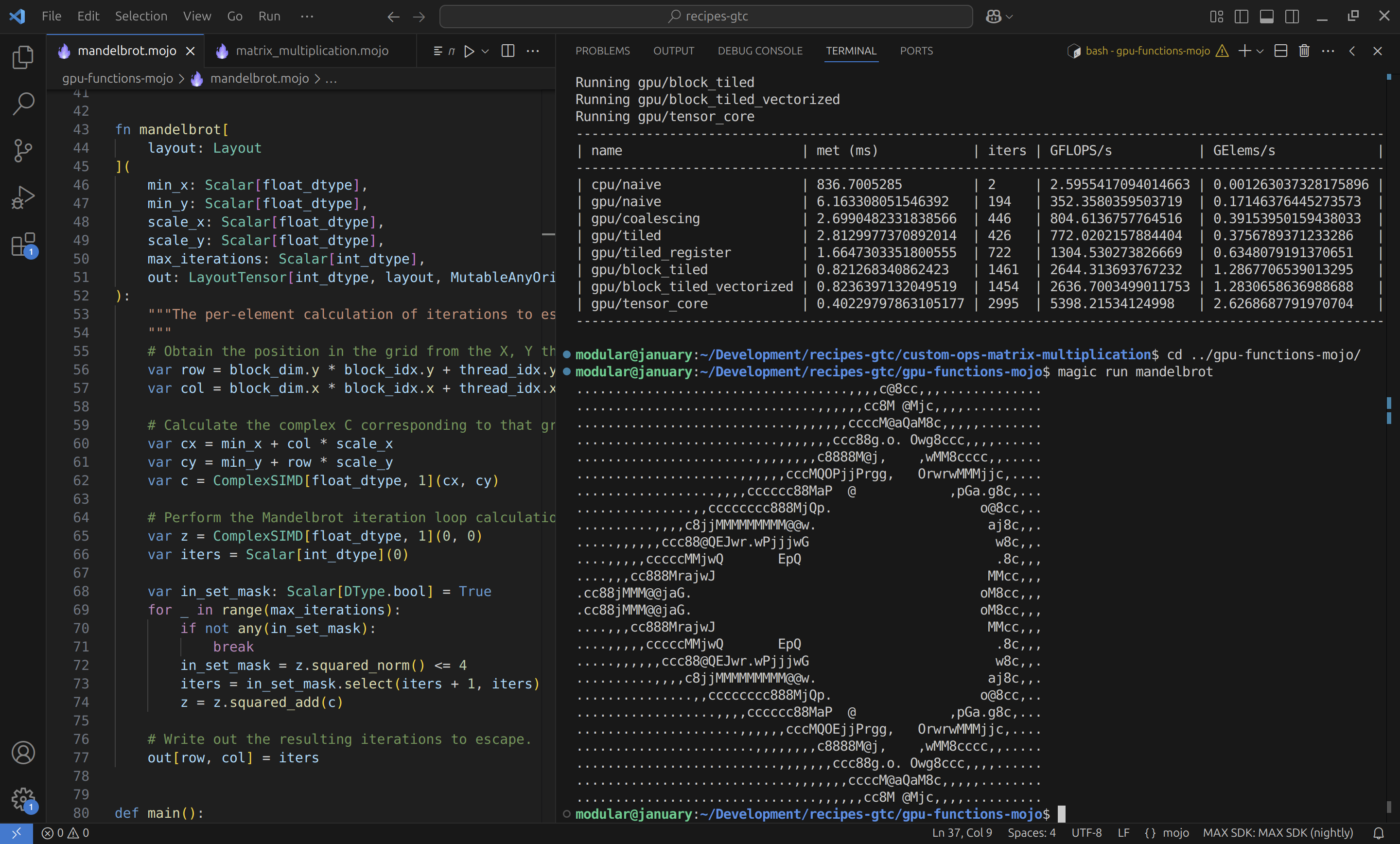
Simplified GPU programming with Mojo🔥
Beyond the the Open-AI compatible endpoint, MAX is also great for AI researchers and developers who want to unlock the full power of the GPU for novel applications. Our mission is to make "easy things work" without taking power or control away from you–we want to give you superpowers over AI.
MAX and Mojo have fundamentally reimagined GPU programming. If you're familiar with CUDA C++, you'll feel right at home with a powerful GPU programming model that offers all the benefits of Mojo's modern language features.
Check out our examples on MAX Builds, which recreate the first few chapters from the popular textbook "Programming Massively Parallel Processors," but translated into Mojo. From the basic principles of vector addition to advanced patterns like high-performance matrix multiplication, we have examples to help you master device-independent GPU programming. Examples include:
- An introduction to GPU programming that demonstrates writing custom operations to render the Mandelbrot set using Mojo's built-in complex number type.
- An example of implementation of Fused Attention, showing how to write custom operators using the MAX Graph API.
- Progressive optimizations for matrix multiplication, teaching how to leverage MAX's tensor layout API for GPU programming.
You can download these recipes directly using Magic, making starting your GPU programming journey even easier. Also, don't miss the first chapter of our comprehensive guide to GPU programming in the MAX documentation!
Experience the future of AI inference today!
MAX 25.2 represents a significant leap forward in our mission to make high-performance AI accessible to everyone. Whether running billion-parameter models or building custom GPU-accelerated applications, MAX provides the tools and performance you need.
Ready to get started? Download the latest release, check out our expanded documentation, or join our community to share your experiences and learn from other MAX users.
AI doesn't need to be held back by CUDA–check out MAX and Mojo🔥 today!