


.jpeg)
Compute fragmentation is holding AI back
AI is powered by a virtuous circle of data, algorithms (“models”), and compute. Growth in one pushes needs in the others and can grossly affect the developer experience on aspects like usability and performance. Today, we have more data and more AI model research than ever before, but compute isn’t scaling at the same speed due to … well, physics.
If you’ve followed the evolution of AI and hardware, you’ve probably heard that Moore’s law is ending. The rate of performance improvement in single-core processors is no longer doubling every 18 months, as has been true for the last 60 years. Beyond the physical limitations of continuing to make transistors smaller and smaller (e.g., excess power usage and heat due to current leakage), performance has become increasingly constrained by memory latency, which has grown much slower than processing speeds.
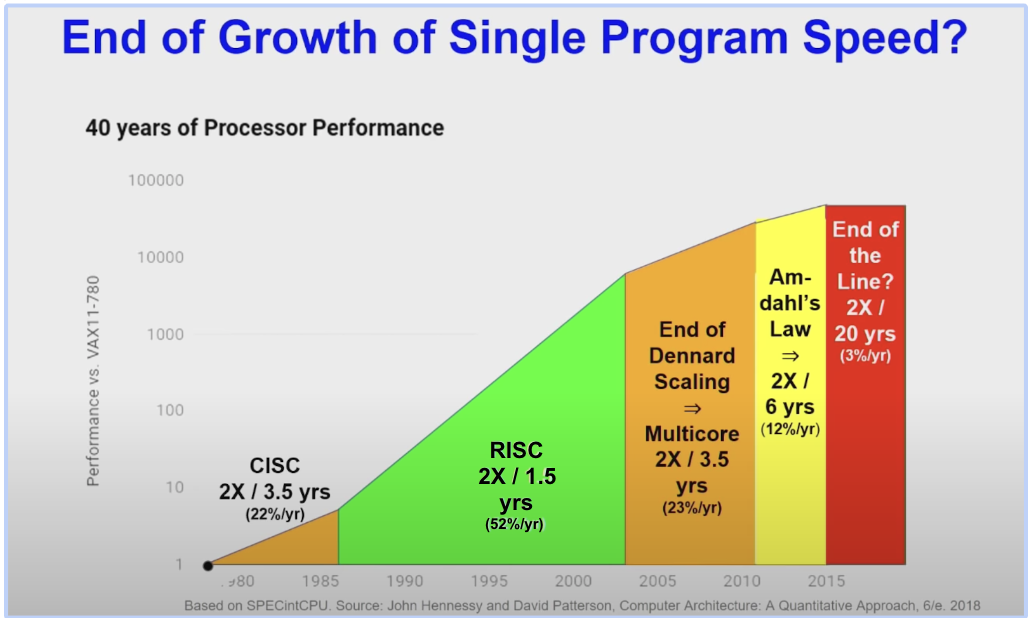
Yet, the need for more AI compute has continued to grow as models become larger and larger and more enterprise data is created and processed on the edge. As a result, squeezing performance from hardware has become one of the main focuses of the industry.
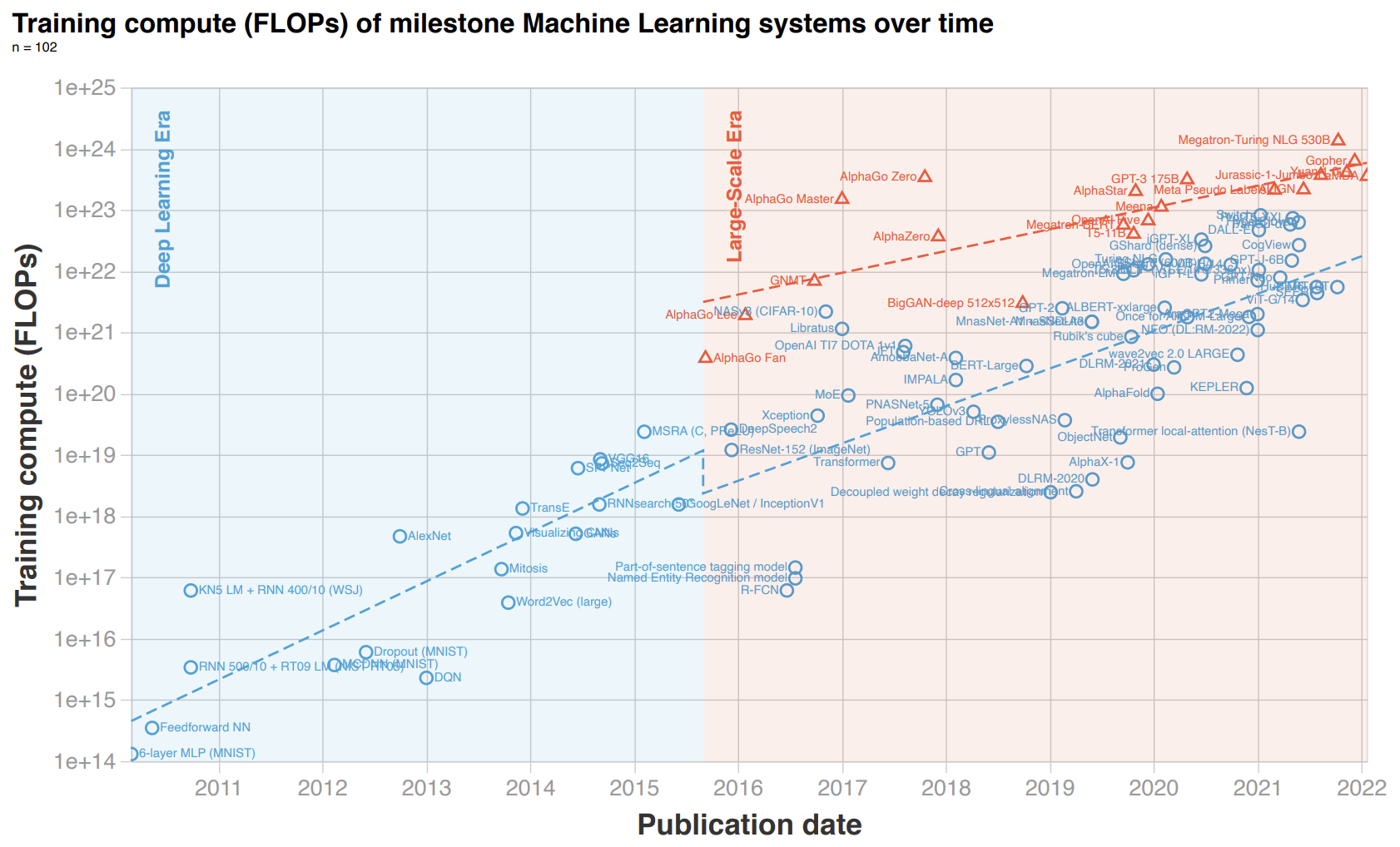
So how is compute fragmentation holding AI back? With traditional CPUs not scaling to meet the need for more compute, the only way forward has been to create parallel and domain-specific hardware that is less general, but that does a few AI-related things really well — like graphics processing units (GPUs), tensor processing units (TPUs), and other application-specific integrated circuits (ASICs). While these innovations have helped push the industry forward, enabling greater scale and more power-efficient processors in edge devices, the increased diversity of hardware has fragmented the industry and left AI developers struggling to:
- Develop software that fully leverages the hardware’s capabilities and composes with others.
- Express parallel software algorithms on any one device.
- Scale that software across an ecosystem of many devices or even to heterogeneous systems.
Modular is focused on rebuilding the world’s AI infrastructure from the ground up. In this blog series, we’ll talk about how we are taking a fresh approach to solving the industry’s compute fragmentation problem. We will motivate the low-level challenges of building a truly unified solution by focusing on a single operation, matrix multiplication (“matmul”), a critical calculation in machine learning algorithms. To understand why it is hard, though, we will look under the hood of matmul and get into some of the nitty-gritty details of how it works. Don’t say you weren’t warned - this post is about to go deep!
Matrix multiplication, and why it is so hard
Matrices are critical to machine learning systems as a simple way to represent data efficiently — such as input data (e.g., sets of pixels in an image) or the internal workings between the model layers. As a result, multiplying these matrices together makes up a large portion of the total computations in deep learning models. In fact, matmuls make up roughly 45-60% of the total runtime of many popular transformer models like BERT, CLIP, and even ChatGPT. Matmuls are also critical to computing the convolution operation that forms the foundation of most computer vision models, and makes up the backbone of many high-performance computing (”HPC”) applications.
Given its importance, there has been extensive research on writing efficient matmul algorithms. Papers from the 60s, 70s, 80s, 90s, 2000s, to the present day exist that try to solve the problem with the hardware of that era.

But the conceptual matmul algorithm isn’t what makes it difficult. Instead, the challenge is writing a matmul fast enough to achieve state-of-the-art performance across all the hardware, model, and data diversity in the AI industry. It is even harder to make it compose with all other AI operators.
Hardware
Each device used to run AI models has different characteristics, including different memory hierarchies and different multiply and accumulate units (MAC).
For example, CPUs employ a hierarchy of memory from slow RAM to increasingly faster caches — Level-3, Level-2, Level-1, and CPU registers. The size of the memory is inversely proportional to its speed — for example, L1 cache access is typically on the order of single nanoseconds, whereas RAM access is on the order of 100 nanoseconds. To get the highest performance matmul, the algorithm itself has to be implemented to efficiently work with the different memory levels and sizes. Raw matrices are too big to fit into the registers or the fastest memory cache at one time, so the challenge is determining how to decompose them into the right sized blocks or “tiles” that maximize usage of the fastest memory.
Moreover, the actual shapes of the units that handle the core matrix functionality differ across hardware. CPUs have traditionally been scalar machines, meaning they process instructions one step at a time, but all CPU vendors have added vector units (SIMD) over the last two decades. GPUs execute single operations across multiple threads (SIMT) to maximize the efficiency of highly parallel, repetitive operations like matmuls. And more specialized hardware takes this further by operating on 2D matrices. Google TPUs are the most well-known, but Apple and Intel have added their own matrix multiplication features called AMX. But while more advanced MAC units have led to improved performance, they have also created a greater need for flexible algorithms that work across scalar, vector, and matrix processors.
.png)
Models
AI models are also quite diverse. While matmuls form the foundation of many models, the matrix sizes used in those matmuls can vary significantly. For example, models have different input shapes (like varying sequence lengths), different internal shapes (i.e., the matrices that are being multiplied together as part of the hidden layers of the model), and even different batch sizes (critical for training and inference efficiencies). As a result, matmuls come in hundreds of different shapes in production, which makes decomposing them into blocks that maximize memory efficiency challenging.
.png)
Data
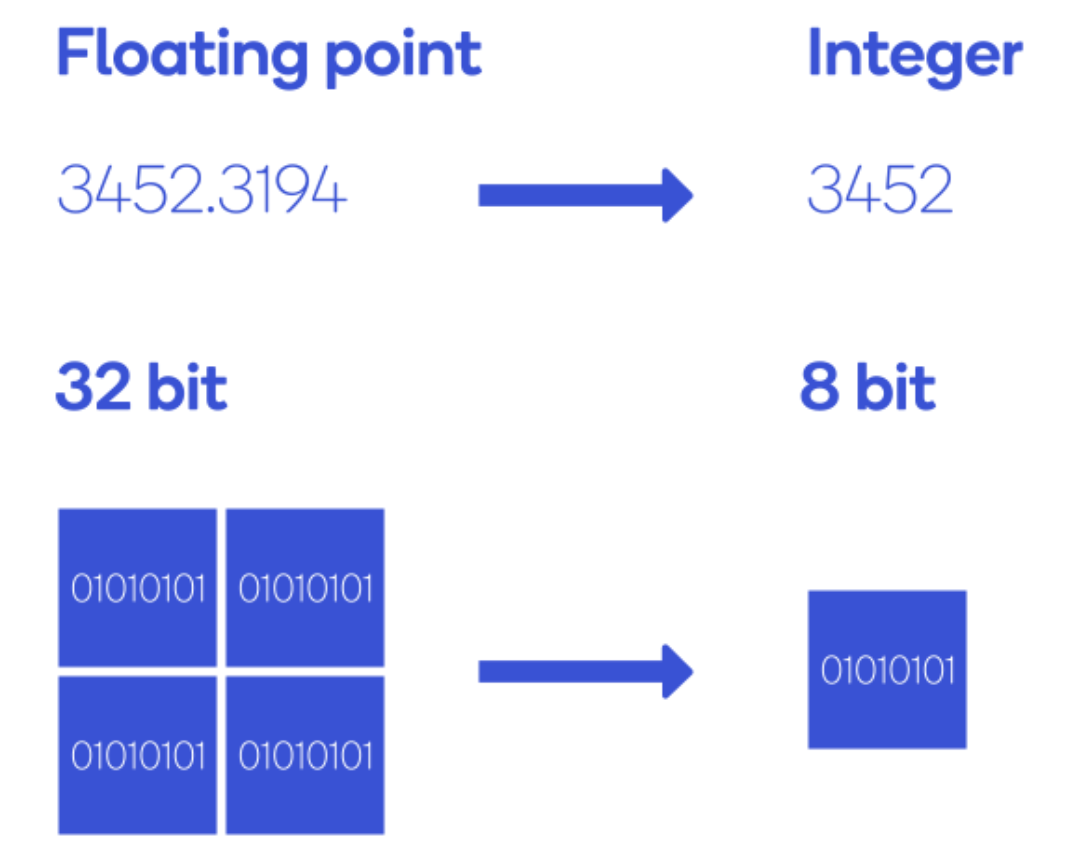
Lastly, your data can also be diverse. Most readers will be familiar with data diversity in terms of structured and unstructured data, but in this case, we are more concerned with data type (”dtype”). Data in AI models is usually of dtype FP32, but the industry is also adopting lower precision data types like Bfloat16, Int8, and the more exotic FP4 and Int4, to reduce model size and improve performance. Matmul algorithms, then, need to be able to operate on data of many different precisions, depending on the use case.
Current state-of-the-art
So how are today’s most state-of-the-art matmul algorithms actually implemented? Given its importance, matmul is usually one of the first algorithms that hardware vendors optimize, with many providing implementations through their libraries. Intel provides the MKL and OneDNN libraries, AMD provides AOCL and RocBLAS, ARM has performance libraries, Apple has Accelerate, and Nvidia provides CUBLAS.
Across the hardware libraries mentioned above, the current state of the art in terms of efficient implementation is to effectively write assembly code: this means micro-managing the hardware by giving it direct instructions at the lowest level that it understands without abstractions.

The main reason for this? Writing assembly produces the best performance for any one specific use-case because developers who are writing assembly can avoid the unpredictability of compilers, which translate higher-level languages like Python & C++ down to assembly, and can perform optimizations that are hard for the compiler to do because compilers must generalize. Importantly, they can leverage instructions and patterns that the compiler is unaware of because extending the compiler to support new hardware features takes time.
Hand-written assembly kernels don’t scale!
But does this actually solve the fragmentation issue for users? While writing in assembly maximizes performance for any individual example, it’s not portable, doesn’t compose, doesn’t scale, and isn’t user-friendly. Think about it: how can a small number of specialized experts, who hand write and tune assembly code, possibly scale their work to all the different configurations while also incorporating their work into all the AI frameworks?! It’s simply an impossible task.
.png)
Portability
Because assembly is written with a hardware-specific interface called an instruction set architecture (ISA) it is not portable across different hardware platforms. In fact, assembly can’t even deliver the best performance across multiple generations of chips from the same vendor!
Further, even if you have target hardware in mind when developing your model, there are still two big practical problems:
- In the cloud, you don’t have control over the specific hardware it runs on. “But I’ve selected an instance that’s perfect for my model” you say. The truth is that instance types on some cloud providers like AWS don’t guarantee a specific CPU type. For example, if you select a c5.4xlarge instance, you could get an older generation Intel SkyLake processor or a newer Cascade Lake processor. Assembly cannot adapt and give you the best performance for the specific chip your code runs on.
- Your product will continue to evolve rapidly, and you may want to move to a different hardware architecture altogether. Auguring in on one specific configuration will limit your flexibility to adapt as your model requirements change or when a new generation of hardware comes out.
Scalability and composability
As we discussed earlier, there are many AI models, leading to hundreds of different matmul shapes. Using assembly-based libraries means selecting specific processor instructions that hardcode parameters like memory tiling sizes. These hard-coded assembly libraries can be tuned well for a specific tensor shape but require a different implementation for others. As a result, many existing kernel libraries swell to be gigabytes in size (e.g., MKL is 3.2GB and cuDNN can be up to 2.5GB). This becomes a problem when the size of these libraries impacts container build times, if you deploy to the edge where this is impractical, or if you want to deploy new innovations and research that these vendors haven’t manually specialized yet.
Looking at the bigger picture, high-performance matmuls are indeed important for performance. But to get the best results, matmuls can be executed together with other operations such as elementwise, strided accesses, broadcasts, etc. Operator fusion provides significant performance improvements by reducing memory traffic - but the challenge is that there are thousands of AI operators. Furthermore, models use many permutations of different operations in combination, and (while some have tried!) it isn’t practical to hand-fuse all the important combinations, particularly when research is driving AI forward so fast.
User-friendliness
And finally, writing assembly is not user-friendly or good for cross-organization productivity. Assembly programming has limited features available in modern programming languages like parameterization and object-oriented programming and does not provide great tooling for debugging, code coverage, testing, etc. While the reality is that most researchers looking to write new operations are most comfortable in Python, it has well-known performance issues, so organizations end up having to hire expensive specialists to bridge the gap.
Stay tuned
For AI to reach its true potential, compute fragmentation needs to be solved. AI software developers need to be able to seamlessly take full advantage of existing hardware and the next generation of hardware innovations when they become available. But as you can see, solving this problem is not easy. Diversity in hardware, models, and data means that every existing solution on the market is only just a “point solution” to a much broader problem.
Modular is solving this problem - stay tuned for part 2 of the blog, in which we outline our approach and show the revolutionary benefits. And if you are excited about solving some of the most challenging and complex problems, go to modular.com/careers and apply!



